Giáo dục mở - tài nguyên giáo dục mở
Ứng dụng và phát triển
Preprint Servers
Theo: https://info.orcid.org/documentation/workflows/preprint-workflow/
Trước khi xuất bản chính thức trên một tạp chí, các bài báo theo truyền thống được bình duyệt ngang hàng. Thường thì tạp chí sẽ chỉ xuất bản bài báo một khi các biên tập viên hài lòng là các tác giả đã giải quyết bất kỳ lo ngại nào có thể phát sinh từ quy trình bình duyệt đó.
Chúng tôi biết rằng quy trình này có thể mất vài thời gian, và rằng không phải tất cả các ngành đều xuất bản tất cả các kết quả đầu ra lên các tạp chí. May thay, các nhà nghiên cứu có khả năng làm cho các kết quả đầu ra của họ sẵn sàng bằng việc tải lên một máy chủ preprint, tới lượt nó có thể cập nhật hồ sơ ORCID của họ nếu máy chủ preprint đó là một thành viên của ORCID. Quy trình cơ bản là như sau:
Tác giả gửi đệ trình bài báo tới máy chủ preprint
Dịch vụ của máy chủ preprint thu thập ORCID id của tác giả được xác thực và yêu cầu sự cho phép để tương tác với hồ sơ của họ, và lưu trữ sự cho phép đó.
Khi bản preprint đó được chấp nhận đối với máy chủ đó thì nhà cung cấp:
Đưa ORCID iD vào siêu dữ liệu của riêng nó, và bất kỳ siêu dữ liệu DOI nào.
Thêm bản preprint vào hồ sơ ORCID của tác giả, bao gồm cả ID của preprint đó (ví dụ, một DOI) và sử dụng dạng tác phẩm preprint với mối quan hệ “Self” (Bản thân). Điều này sẽ kết nối người đó với preprint đó.
Hiển thị logo iD xác thực cùng với tên tác giả của preprint đó và liên kết nó với hồ sơ ORCID của họ.
Dịch vụ đó cũng cho phép thu thập các iD xác thực cho bất kỳ đồng tác giả nào bằng việc gửi thư điện tử cho họ và yêu cầu họ xác thực và khẳng định đóng góp của họ.
Nếu bài báo đó được chấp nhận xuất bản trên một tạp chí được bình duyệt ngang hàng sau đó, thì nhà xuất bản có thể thêm bài báo trên tạp chí được bình duyệt ngang hàng vào hồ sơ ORCID, và đưa 2 mã nhận diện: một DOI cho bài báo trên tạp chí với quan hệ ‘Self’ và một DOI hoặc mã nhận diện của bản preprint gốc với quan hệ ‘Version of’ (Phiên bản của) nếu họ biết điều đó. Điều này sẽ nhóm các phiên bản lại cùng nhau trong hồ sơ ORCID, điều là hữu ích cho nhà nghiên cứu và những người xem hồ sơ đó.
Ví dụ

Liên kết bản preprint với các phiên bản được bình duyệt ngang hàng hoặc khác
ORCID hỗ trợ nhiều dạng quan hệ mã nhận diện bên ngoài:
Self - Tự bản thân: mã nhận diện tham chiếu chỉ tới tác phẩm đó và có thể được nhóm với các tác phẩm khác có cùng mã nhận diện. Ví dụ là một DOI
Part of - Phần của: tác phẩm là một phần của mã nhận diện này và không thể được nhóm với các tác phẩm khác. Ví dụ là một ISSN
Version of - Phiên bản của: các mã nhận diện áp dụng cho các phiên bản lựa chọn thay thế của tác phẩm và có thể được nhóm với self và version của các mã nhận diện. Được sử dụng để liên kết nhiều phiên bản của một tập hợp dữ liệu cùng nhau, hoặc để nhóm các preprint với phiên bản tài liệu được xuất bản.
Funded by - Được cấp vốn bởi: Các mã nhận diện này được sử dụng để liên kết việc cấp vốn với kết quả đầu ra nghiên cứu. Các mã nhận diện đó không được sử dụng trong việc tạo nhóm.
Các dạng mối quan hệ được sử dụng cho việc tạo nhóm các tác phẩm trong các hồ sơ ORCID của người sử dụng. Một tác phẩm y hệt có thể được thêm vào hồ sơ ORCID từ các nguồn khác nhau: nhiều kết nối đó làm cho thông tin về hồ sơ ORICD xác thực hơn. Ở những nơi các tác phẩm đó có một mã nhận diện chung (như một DOI, ISBN, .v.v.), chúng tự động được nhóm lại cùng nhau vì chúng đại diện cho một hạng mục y hệt. Lưu ý là vài mã nhận diện là phân biệt chữ hoa chữ thường và những gì xuất hiện sẽ là 2 phiên bản của cùng một mã nhận diện (ví dụ, “11abC” và “11ABC”) sẽ không nhóm được, trong khi vài mã nhận diện không phân biệt chữ hoa chữ thường và sẽ vẫn nhóm được ngay cả nếu các trường hợp đó là khác nhau (ví dụ, “10.125/1xyZ” và “10.125/1XYZ”). Nếu một tác phẩm không có mã nhận diện, nó không thể được nhóm.
Các lợi ích
Mọi thứ thường không đơn giản như vậy. Các iD và quyền ORCID có khả năng sẽ cần phải được chuyển từ hệ thống đệ trình sang hệ thống sản xuất và thậm chí có thể không có hệ thống để tác giả tương tác.
Chúng tôi vẫn nghĩ điều đó đáng làm. ORCID có thể giúp hợp lý hóa quy trình xuất bản, cải thiện quản lý tác giả và các cơ sở dữ liệu của người bình duyệt, và cải thiện độ chính xác tìm kiếm các kho dựa vào tên.
Các nhà xuất bản sử dụng ORCID để liên kết rõ ràng các tác giả và những người bình duyệt - và tất cả các phương án tên của họ - với tác phẩm nghiên cứu của họ, bằng việc nhúng các ORCID iD vào siêu dữ liệu ấn phẩm của họ và hiển thị chúng khi xuất bản hoàn thành. Bằng việc đưa các iD xác thực vào siêu dữ liệu của bạn, bạn có thể giải phóng các nhà nghiên cứu khỏi việc phải cập nhật thủ công hồ sơ ORCID của họ, giúp tăng tốc truyền thông các tác phẩm nghiên cứu, và giảm thiểu rủi ro các lỗi. Bạn cũng có thể sử dụng dữ liệu từ hồ sơ ORCID như tên các nhà nghiên cứu, lịch sử giáo dục, và các cơ sở liên kết hiện hành để nhập liệu cho các hồ sơ trong hệ thống của riêng bạn để tiết kiệm thời gian của người sử dụng của bạn và giảm thiểu các lỗi.
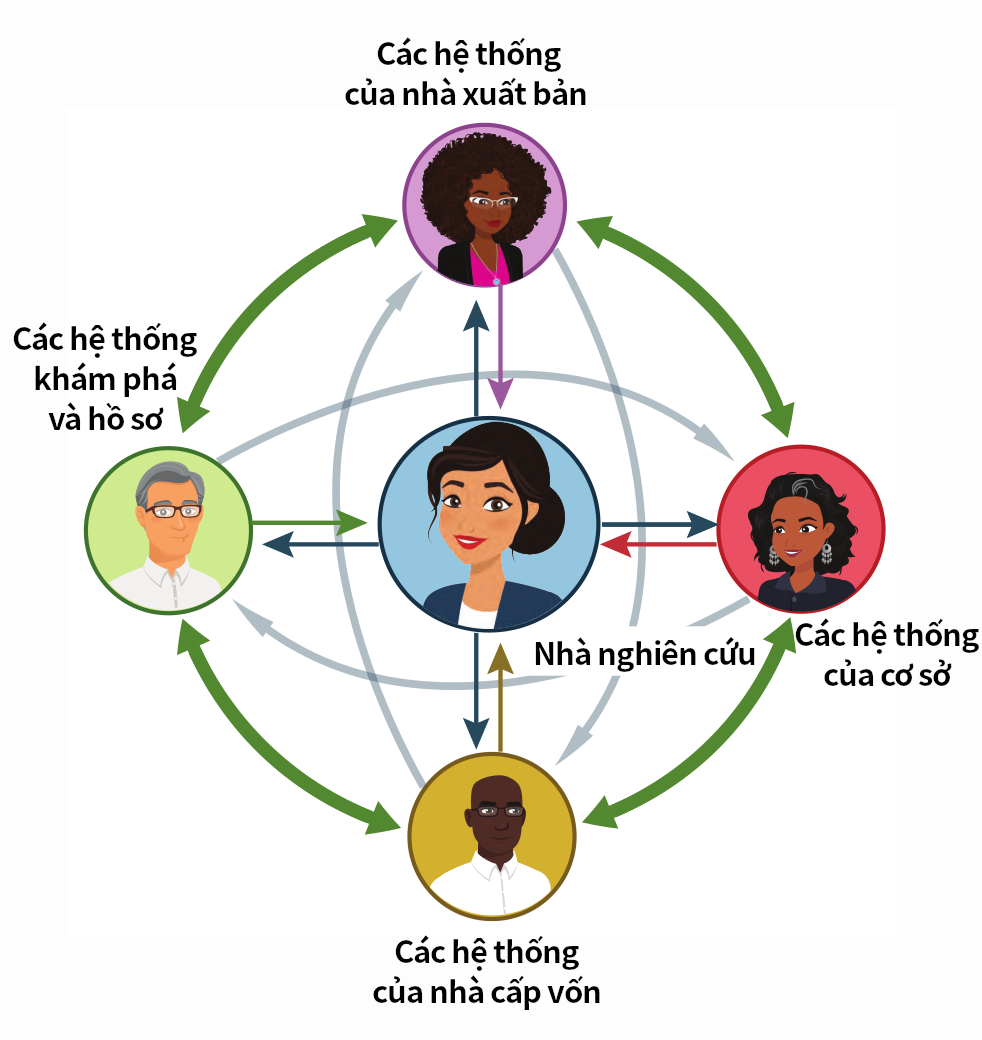
Các nhà nghiên cứu nằm ở tâm điểm của mọi điều mà các nhà xuất bản học thuật và nghiên cứu làm. Thông tin chính xác về tác giả và người bình duyệt là rất quan trọng cho việc đánh chỉ mục, tìm kiếm và phát hiện, theo dõi xuất bản, cấp vốn và thừa nhận ghi công sử dụng tài nguyên, và hỗ trợ cho bình duyệt ngang hàng.
Tham khảo thêm các bản dịch liên quan tới các quy trình làm việc của ORCID ở đây.
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Trang Web này được thành lập theo Quyết định số 142/QĐ-HH do Chủ tịch Hiệp hội các trường đại học, cao đẳng Việt Nam – AVU&C (Association of Vietnam Universities and Colleges), GS.TS. Trần Hồng Quân ký ngày 16/09/2019, ngay trước thềm của Hội thảo ‘Xây dựng và khai thác tài nguyên giáo dục mở’ do 5...
 Tín hiệu CC: Những việc chúng tôi đã và đang thực hiện
Tín hiệu CC: Những việc chúng tôi đã và đang thực hiện
 Tích hợp các lựa chọn vào tiêu chuẩn mở: Tín hiệu CC và Tiêu chuẩn RSL
Tích hợp các lựa chọn vào tiêu chuẩn mở: Tín hiệu CC và Tiêu chuẩn RSL
 Làm thế nào để đánh giá định lượng năng lực Tài nguyên Giáo dục Mở? Bài học từ việc đánh giá năng lực số của châu Âu
Làm thế nào để đánh giá định lượng năng lực Tài nguyên Giáo dục Mở? Bài học từ việc đánh giá năng lực số của châu Âu
 DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 3: Các giai đoạn trong quá trình phát triển DigComp 3.0
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 2: Chuẩn đầu ra học tập của DigComp 3.0. CHUẨN ĐẦU RA HỌC TẬP. LĨNH VỰC 5: Nhận diện và giải quyết vấn đề
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 2: Chuẩn đầu ra học tập của DigComp 3.0. CHUẨN ĐẦU RA HỌC TẬP. LĨNH VỰC 4: An toàn, phúc lợi và sử dụng có trách nhiệm
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 2: Chuẩn đầu ra học tập của DigComp 3.0. CHUẨN ĐẦU RA HỌC TẬP. LĨNH VỰC 3: Tạo lập nội dung
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 3: Các giai đoạn trong quá trình phát triển DigComp 3.0
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 2: Chuẩn đầu ra học tập của DigComp 3.0. CHUẨN ĐẦU RA HỌC TẬP. LĨNH VỰC 5: Nhận diện và giải quyết vấn đề
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 2: Chuẩn đầu ra học tập của DigComp 3.0. CHUẨN ĐẦU RA HỌC TẬP. LĨNH VỰC 4: An toàn, phúc lợi và sử dụng có trách nhiệm
DigComp 3.0: Khung năng lực số châu Âu. Phụ lục 2: Chuẩn đầu ra học tập của DigComp 3.0. CHUẨN ĐẦU RA HỌC TẬP. LĨNH VỰC 3: Tạo lập nội dung
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
 Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
 Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
 Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
 ORCID - Quy trình làm việc
ORCID - Quy trình làm việc
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
 Năm Khoa học Mở & Chuyển đổi sang Khoa học Mở - Tổng hợp các bài liên quan
Năm Khoa học Mở & Chuyển đổi sang Khoa học Mở - Tổng hợp các bài liên quan
 ‘Bộ công cụ Khoa học Mở của UNESCO’ - Các bản dịch sang tiếng Việt
‘Bộ công cụ Khoa học Mở của UNESCO’ - Các bản dịch sang tiếng Việt
 Định nghĩa các khái niệm liên quan tới Khoa học Mở
Định nghĩa các khái niệm liên quan tới Khoa học Mở
 ‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
 Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu