Giáo dục mở - tài nguyên giáo dục mở
Ứng dụng và phát triển

Retrieval Augmented Generation (RAG)
Theo: https://www.promptingguide.ai/techniques/rag
Các mô hình ngôn ngữ mục đích chung có thể được tinh chỉnh để đạt được vài nhiệm vụ chung chẳng hạn như phân tích cảm xúc và nhận diện thực thể được đặt tên. Các nhiệm vụ đó thường không đòi hỏi kiến thức nền tảng bổ sung.
Đối với các tác vụ phức tạp và đòi hỏi nhiều kiến thức hơn, có thể xây dựng một hệ thống dựa trên mô hình ngôn ngữ, cho phép truy cập các nguồn kiến thức bên ngoài để hoàn thành tác vụ. Điều này cho phép tính nhất quán về dữ kiện cao hơn, cải thiện độ tin cậy của các phản hồi được tạo ra và giúp giảm thiểu vấn đề "ảo giác".
Các nhà nghiên cứu Meta AI đã giới thiệu một phương pháp gọi là Tạo sinh Tăng cường Truy xuất - RAG (Retrieval Augmented Generation) để giải quyết các tác vụ đòi hỏi nhiều kiến thức như vậy. RAG kết hợp một thành phần truy xuất thông tin với một mô hình tạo sinh văn bản. RAG có thể được tinh chỉnh và kiến thức nội bộ của nó có thể được sửa đổi một cách hiệu quả mà không cần phải đào tạo lại toàn bộ mô hình.
RAG lấy dữ liệu đầu vào và truy xuất một tập hợp các tài liệu liên quan/hỗ trợ dựa trên một nguồn (ví dụ: Wikipedia). Các tài liệu được nối theo ngữ cảnh với lời nhắc nhập ban đầu và được đưa vào trình tạo sinh văn bản, nơi tạo ra kết quả cuối cùng. Điều này làm cho RAG thích ứng với các tình huống mà dữ kiện có thể thay đổi theo thời gian. Điều này rất hữu ích vì kiến thức tham số của LLM là tĩnh. RAG cho phép các mô hình ngôn ngữ bỏ qua việc đào tạo lại, cho phép truy cập thông tin mới nhất để tạo sinh các đầu ra đáng tin cậy thông qua phương pháp tạo sinh dựa trên truy xuất.
Lewis và cộng sự, (2021) đã đề xuất một công thức tinh chỉnh đa năng cho RAG. Một mô hình seq2seq được đào tạo trước được sử dụng làm bộ nhớ tham số và một chỉ mục vectơ dày đặc của Wikipedia được sử dụng làm bộ nhớ phi tham số (được truy cập bằng bộ truy xuất thần kinh được đào tạo trước). Dưới đây là tổng quan về cách thức hoạt động của phương pháp này:
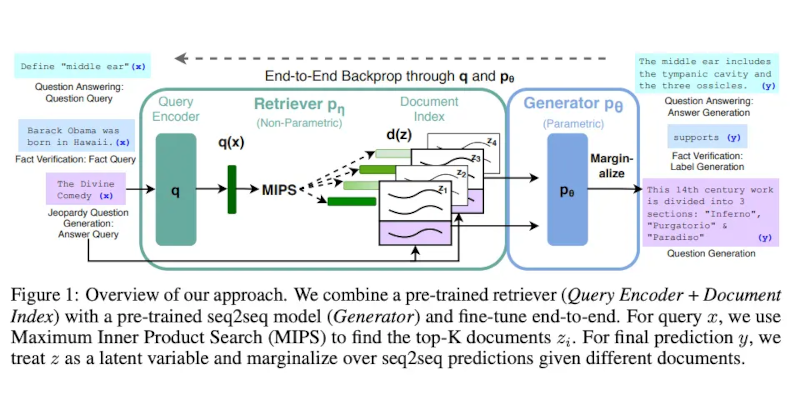
Image Source: Lewis et el. (2021)
RAG hoạt động mạnh mẽ trên một số tiêu chuẩn như Natural Questions, WebQuestions và CuratedTrec. RAG tạo ra các câu trả lời thực tế, cụ thể và đa dạng hơn khi được kiểm tra trên các câu hỏi MS-MARCO và Jeopardy. RAG cũng cải thiện kết quả xác minh dữ kiện FEVER.
Điều này cho thấy tiềm năng của RAG như một lựa chọn khả thi để cải thiện kết quả của các mô hình ngôn ngữ trong các nhiệm vụ đòi hỏi kiến thức chuyên sâu.
Gần đây, các phương pháp tiếp cận dựa trên bộ truy xuất này đã trở nên phổ biến hơn và được kết hợp với các chương trình LLM phổ biến như ChatGPT để cải thiện khả năng và tính nhất quán của dữ kiện.
Trường hợp sử dụng RAG: Tạo sinh tiêu đề bài báo học máy thân thiện
Dưới đây, chúng tôi đã chuẩn bị một hướng dẫn sổ tay giới thiệu việc sử dụng các Mô hình Ngôn ngữ Lớn - LLM (Large Language Model) nguồn mở để xây dựng hệ thống RAG nhằm tạo sinh tiêu đề bài báo học máy ngắn gọn và súc tích:
Tài liệu tham khảo
Tạo sinh Tăng cường Truy xuất cho Mô hình Ngôn ngữ Lớn: Khảo sát (tháng 12 năm 2023)
Tạo sinh Tăng cường Truy xuất: Hợp lý hóa việc tạo lập các mô hình xử lý ngôn ngữ tự nhiên thông minh (tháng 9 năm 2020)
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
Tác giả: admin
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Trang Web này được thành lập theo Quyết định số 142/QĐ-HH do Chủ tịch Hiệp hội các trường đại học, cao đẳng Việt Nam – AVU&C (Association of Vietnam Universities and Colleges), GS.TS. Trần Hồng Quân ký ngày 16/09/2019, ngay trước thềm của Hội thảo ‘Xây dựng và khai thác tài nguyên giáo dục mở’ do 5...
 Lợi ích của Văn hóa Mở là gì? Một ấn phẩm CC mới
Lợi ích của Văn hóa Mở là gì? Một ấn phẩm CC mới
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 01 và 02/07/2026.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 01 và 02/07/2026.
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No1/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 29 và 30/06/2026.
Tài liệu thuộc phạm vi công cộng này nằm ở đâu trên thế giới…? Giúp người dùng tham khảo các tổ chức lưu trữ
Báo cáo đánh giá nhu cầu của CC về các công cụ thuộc phạm vi công cộng trong lĩnh vực di sản văn hóa hé lộ những hiểu biết quan trọng.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No1/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 29 và 30/06/2026.
Tài liệu thuộc phạm vi công cộng này nằm ở đâu trên thế giới…? Giúp người dùng tham khảo các tổ chức lưu trữ
Báo cáo đánh giá nhu cầu của CC về các công cụ thuộc phạm vi công cộng trong lĩnh vực di sản văn hóa hé lộ những hiểu biết quan trọng.
 Di sản Mở
Di sản Mở
 ‘Cơ sở hạ tầng trực tuyến cho Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Cơ sở hạ tầng trực tuyến cho Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
 Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
 Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
 Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
 ORCID - Quy trình làm việc
ORCID - Quy trình làm việc
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
 Loạt bài về Khoa học Mở (KHM): Định nghĩa các khái niệm của KHM; Bộ công cụ KHM của UNESCO bản tiếng Việt; Năm KHM và chuyển đổi sang KHM;
Loạt bài về Khoa học Mở (KHM): Định nghĩa các khái niệm của KHM; Bộ công cụ KHM của UNESCO bản tiếng Việt; Năm KHM và chuyển đổi sang KHM;
 ‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
 Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
 Các thành phần cơ bản trong kế hoạch tổng thể xây dựng chính sách tài nguyên giáo dục mở – OER (Open Educational Resources) - bản toàn văn
Các thành phần cơ bản trong kế hoạch tổng thể xây dựng chính sách tài nguyên giáo dục mở – OER (Open Educational Resources) - bản toàn văn