Giáo dục mở - tài nguyên giáo dục mở
Ứng dụng và phát triển

Reflexion
Theo: https://www.promptingguide.ai/techniques/reflexion
Phản xạ là một khuôn khổ để củng cố các tác nhân dựa trên ngôn ngữ thông qua phản hồi ngôn ngữ. Theo Shinn và cộng sự (2023), "Phản xạ là một mô hình mới cho việc củng cố 'bằng lời nói', tham số hóa chính sách thành mã hóa bộ nhớ của tác nhân kết hợp với các tham số LLM được lựa chọn."
Ở cấp độ cao, Phản xạ chuyển đổi phản hồi (dạng ngôn ngữ tự do hoặc dạng vô hướng) từ môi trường thành phản hồi ngôn ngữ, còn được gọi là tự phản xạ (self-reflection), được cung cấp làm bối cảnh cho tác nhân LLM trong hành động tiếp theo. Điều này giúp tác nhân học hỏi nhanh chóng và hiệu quả từ những sai lầm trước đó, dẫn đến cải thiện hiệu suất trong nhiều tác vụ nâng cao.
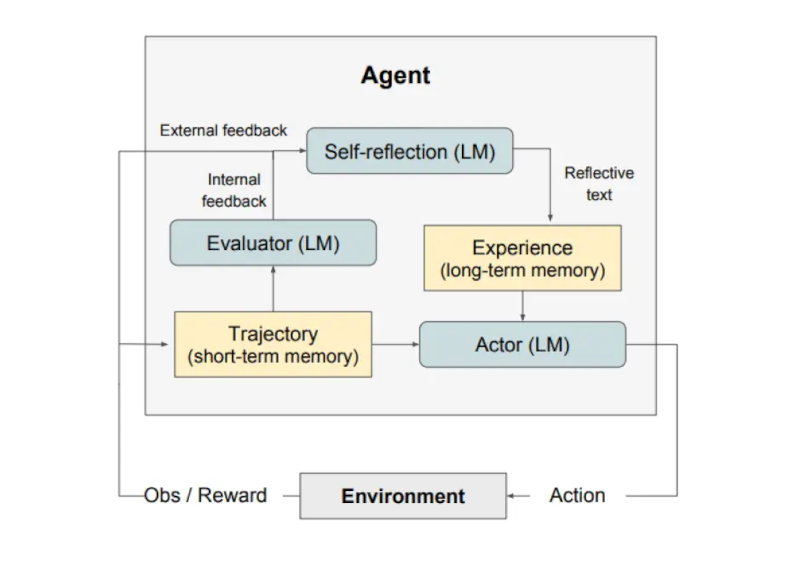
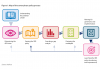
Như được minh họa trong hình ở trên, Reflexion gồm 3 mô hình riêng biệt:
Một Actor (Người hành động): Tạo văn bản và hành động dựa trên các quan sát trạng thái. Actor thực hiện một hành động trong môi trường và nhận được một quan sát, từ đó tạo ra một quỹ đạo. Chuỗi Tư duy - CoT (Chain-of-Thought) và ReAct được sử dụng làm mô hình Actor. Một thành phần bộ nhớ cũng được thêm vào để cung cấp thêm ngữ cảnh cho tác nhân.
Một Evaluator (Người đánh giá): Chấm điểm các kết quả đầu ra do Actor tạo ra. Cụ thể, nó lấy đầu vào là một quỹ đạo đã được tạo ra (còn được gọi là bộ nhớ ngắn hạn) và đưa ra điểm thưởng. Các hàm thưởng khác nhau được sử dụng tùy thuộc vào nhiệm vụ (LLM và phương pháp tìm kiếm dựa trên quy tắc được sử dụng cho các nhiệm vụ ra quyết định).
Tự phản ánh (Self-Reflection): Tạo ra các tín hiệu củng cố bằng lời nói để hỗ trợ Actor trong việc tự cải thiện. Vai trò này được thực hiện bởi một LLM và cung cấp phản hồi có giá trị cho các thử nghiệm trong tương lai. Để tạo ra phản hồi cụ thể và có liên quan, điều cũng được lưu trữ trong bộ nhớ, mô hình tự phản ánh sử dụng tín hiệu thưởng, quỹ đạo hiện tại và bộ nhớ liên tục của nó. Những kinh nghiệm này (được lưu trữ trong bộ nhớ dài hạn) được tác nhân tận dụng để cải thiện nhanh chóng quá trình ra quyết định.
Tóm lại, các bước chính của quy trình Reflexion là a) xác định một nhiệm vụ, b) tạo một quỹ đạo, c) đánh giá, d) thực hiện phản ánh, và e) tạo quỹ đạo tiếp theo. Hình dưới đây minh họa các ví dụ về cách một tác nhân Reflexion có thể học cách tối ưu hóa hành vi của mình theo từng bước lặp để giải quyết các nhiệm vụ khác nhau như ra quyết định, lập trình và suy luận. Reflexion mở rộng khuôn khổ ReAct bằng cách giới thiệu các thành phần tự đánh giá, tự phản ánh và bộ nhớ.
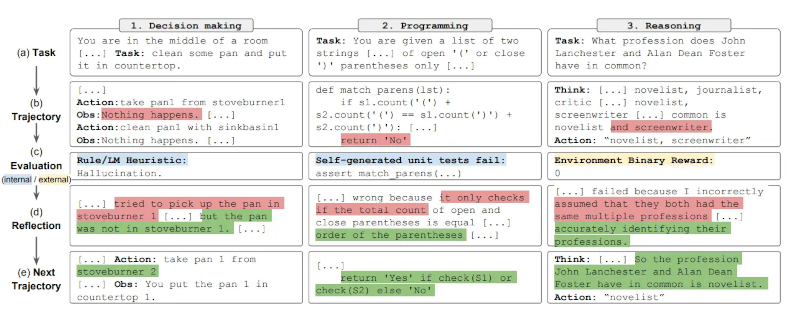
Kết quả
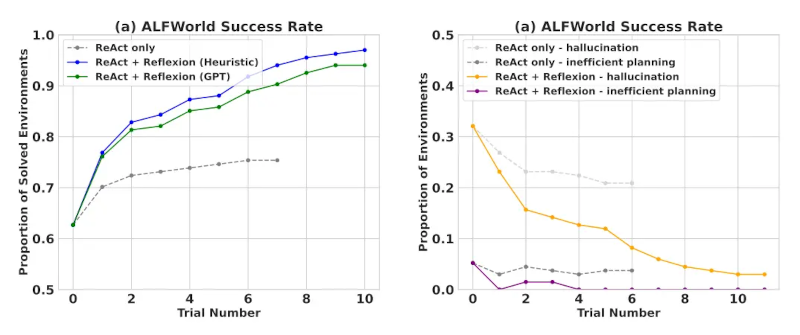
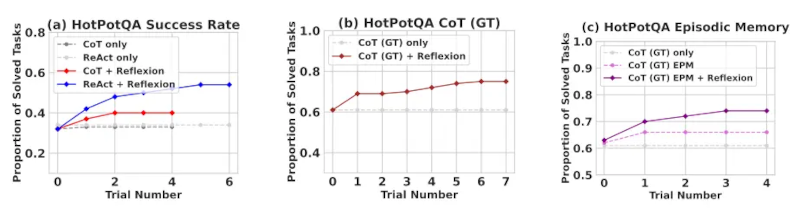
Kết quả thử nghiệm chứng minh rằng các tác nhân Reflexion cải thiện đáng kể hiệu suất trong các tác vụ ra quyết định AlfWorld, các câu hỏi suy luận trong HotPotQA và các tác vụ lập trình Python trên HumanEval.
Khi được đánh giá trên các tác vụ ra quyết định tuần tự (AlfWorld), ReAct + Reflexion vượt trội hơn đáng kể so với ReAct khi hoàn thành 130/134 tác vụ bằng các kỹ thuật tự đánh giá Heuristic và GPT để phân loại nhị phân.
Reflexion vượt trội hơn hẳn so với tất cả các phương pháp cơ bản qua nhiều bước học. Chỉ áp dụng cho suy luận và khi thêm bộ nhớ theo giai đoạn bao gồm quỹ đạo gần nhất, Reflexion + CoT vượt trội hơn so với việc chỉ áp dụng CoT và CoT kết hợp với bộ nhớ theo giai đoạn.
Như tóm tắt trong bảng dưới đây, Reflexion nhìn chung vượt trội hơn các phương pháp tiên tiến trước đây về viết mã Python và Rust trên MBPP, HumanEval và Leetcode Hard.

Khi nào sử dụng Reflexion?
Reflexion phù hợp nhất cho các trường hợp sau:
Tác nhân cần học hỏi từ quá trình thử và sai: Reflexion được thiết kế để giúp tác nhân cải thiện hiệu suất bằng cách suy ngẫm về những sai lầm trong quá khứ và kết hợp kiến thức đó vào các quyết định trong tương lai. Điều này làm cho nó phù hợp với các nhiệm vụ mà tác nhân cần học hỏi thông qua quá trình thử và sai, chẳng hạn như ra quyết định, suy luận và lập trình.
Các phương pháp học tăng cường - RL (Reinforcement Learning) truyền thống không thực tế: Các phương pháp học tăng cường (RL) truyền thống thường yêu cầu dữ liệu huấn luyện phong phú và tinh chỉnh mô hình tốn kém. Reflexion cung cấp một giải pháp thay thế nhẹ nhàng, không yêu cầu tinh chỉnh mô hình ngôn ngữ cơ bản, giúp nó hiệu quả hơn về mặt dữ liệu và tài nguyên tính toán.
Cần có phản hồi có sắc thái: Reflexion sử dụng phản hồi bằng lời nói, có thể có sắc thái và cụ thể hơn so với phần thưởng vô hướng được sử dụng trong RL truyền thống. Điều này cho phép tác nhân hiểu rõ hơn về những sai lầm của mình và thực hiện các cải tiến có mục tiêu hơn trong các lần thử tiếp theo.
Khả năng diễn giải và trí nhớ rõ ràng rất quan trọng: Reflexion cung cấp một dạng trí nhớ theo giai đoạn dễ diễn giải và rõ ràng hơn so với các phương pháp RL truyền thống. Quá trình tự phản ánh của tác nhân được lưu trữ trong bộ nhớ, cho phép phân tích và hiểu rõ hơn về quá trình học tập của nó.
Reflexion hiệu quả trong các tác vụ sau:
Ra quyết định tuần tự: Các tác nhân Reflexion cải thiện hiệu suất của chúng trong các tác vụ AlfWorld, bao gồm việc điều hướng qua nhiều môi trường khác nhau và hoàn thành các mục tiêu nhiều bước.
Suy luận: Reflexion đã cải thiện hiệu suất của các tác nhân trên HotPotQA, một tập dữ liệu trả lời câu hỏi yêu cầu suy luận trên nhiều tài liệu.
Lập trình: Các tác nhân Reflexion viết mã tốt hơn trên các điểm chuẩn như HumanEval và MBPP, đạt được kết quả tiên tiến trong một số trường hợp.
Dưới đây là một số hạn chế của Reflexion:
Dựa vào khả năng tự đánh giá: Reflexion dựa vào khả năng của tác nhân trong việc đánh giá chính xác hiệu suất của nó và tạo ra các phản ánh tự phản ánh hữu ích. Điều này có thể là một thách thức, đặc biệt là đối với các tác vụ phức tạp, nhưng dự kiến Reflexion sẽ ngày càng tốt hơn theo thời gian khi các mô hình tiếp tục cải thiện khả năng.
Hạn chế về bộ nhớ dài hạn: Reflexion sử dụng cửa sổ trượt với dung lượng tối đa, nhưng đối với các tác vụ phức tạp hơn, việc sử dụng các cấu trúc nâng cao như nhúng vector hoặc cơ sở dữ liệu SQL có thể mang lại lợi thế.
Hạn chế về tạo mã: Phát triển hướng kiểm thử có những hạn chế trong việc chỉ định các ánh xạ đầu vào-đầu ra chính xác (ví dụ: hàm tạo không xác định và đầu ra hàm bị ảnh hưởng bởi phần cứng).
Nguồn hình ảnh: Reflexion: Tác nhân Ngôn ngữ với Học Tăng cường Bằng Lời
Tài liệu tham khảo
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
Tác giả: admin
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Trang Web này được thành lập theo Quyết định số 142/QĐ-HH do Chủ tịch Hiệp hội các trường đại học, cao đẳng Việt Nam – AVU&C (Association of Vietnam Universities and Colleges), GS.TS. Trần Hồng Quân ký ngày 16/09/2019, ngay trước thềm của Hội thảo ‘Xây dựng và khai thác tài nguyên giáo dục mở’ do 5...
 Lợi ích của Văn hóa Mở là gì? Một ấn phẩm CC mới
Lợi ích của Văn hóa Mở là gì? Một ấn phẩm CC mới
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 01 và 02/07/2026.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 01 và 02/07/2026.
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No1/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 29 và 30/06/2026.
Tài liệu thuộc phạm vi công cộng này nằm ở đâu trên thế giới…? Giúp người dùng tham khảo các tổ chức lưu trữ
Báo cáo đánh giá nhu cầu của CC về các công cụ thuộc phạm vi công cộng trong lĩnh vực di sản văn hóa hé lộ những hiểu biết quan trọng.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No1/2026 tại Trường Cao đẳng Nghề Thành phố Hồ Chí Minh, 29 và 30/06/2026.
Tài liệu thuộc phạm vi công cộng này nằm ở đâu trên thế giới…? Giúp người dùng tham khảo các tổ chức lưu trữ
Báo cáo đánh giá nhu cầu của CC về các công cụ thuộc phạm vi công cộng trong lĩnh vực di sản văn hóa hé lộ những hiểu biết quan trọng.
 Di sản Mở
Di sản Mở
 ‘Cơ sở hạ tầng trực tuyến cho Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Cơ sở hạ tầng trực tuyến cho Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
 Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
 Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
 Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
 ORCID - Quy trình làm việc
ORCID - Quy trình làm việc
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
 Loạt bài về Khoa học Mở (KHM): Định nghĩa các khái niệm của KHM; Bộ công cụ KHM của UNESCO bản tiếng Việt; Năm KHM và chuyển đổi sang KHM;
Loạt bài về Khoa học Mở (KHM): Định nghĩa các khái niệm của KHM; Bộ công cụ KHM của UNESCO bản tiếng Việt; Năm KHM và chuyển đổi sang KHM;
 ‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
 Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
 Các thành phần cơ bản trong kế hoạch tổng thể xây dựng chính sách tài nguyên giáo dục mở – OER (Open Educational Resources) - bản toàn văn
Các thành phần cơ bản trong kế hoạch tổng thể xây dựng chính sách tài nguyên giáo dục mở – OER (Open Educational Resources) - bản toàn văn