Giáo dục mở - tài nguyên giáo dục mở
Ứng dụng và phát triển
Tóm tắt: Chuyển đổi số cần các kho tri thức số, đặc biệt là các kho tri thức số với dữ liệu được chia sẻ và dùng chung, bên cạnh việc lưu trữ và bảo tồn chúng dài lâu. Các nguyên tắc dữ liệu FAIR đã và đang nổi lên như là các nguyên tắc điều hành và quản lý dữ liệu tốt, chuẩn mực, được thế giới thừa nhận. FAIR là gì và vì sao các trung tâm tri thức số cần áp dụng FAIR là nội dung của bài viết này.
Các từ khóa: FAIR; nguyên tắc dữ liệu FAIR; (siêu) dữ liệu FAIR; tìm thấy được; truy cập được; tương hợp được; sử dụng lại được.
Summary: Digital transformation requires digital knowledge repositories, especially the ones with shared and shared data, in addition to long-term storage and preservation. The FAIR Data Principles have been emerging as internationally recognized, standard, good data governance and management principles. What is FAIR and why digital knowledge centers need to apply FAIR is the content of this article.
Keywords: FAIR; FAIR data principles; FAIR (meta)data; findable; accessible; interoperable; reusable.
1. Đặt vấn đề
Ngày 23/11/2021, tại phiên thứ 41 Hội nghị Toàn thể UNESCO, 193 quốc gia thành viên đã thông qua Khuyến nghị Khoa học Mở[1], biến Khoa học Mở thành một xu thế không thể đảo ngược của thế giới ngày nay. Như một công cụ thiết lập tiêu chuẩn quốc tế đầu tiên về khoa học mở, “Khuyến nghị này đưa ra định nghĩa chung, các giá trị, các nguyên tắc và các tiêu chuẩn được chia sẻ cho khoa học mở ở mức quốc tế và đề xuất một tập hợp các hành động có lợi cho việc vận hành khoa học mở một cách công bằng và bình đẳng cho tất cả mọi người ở các mức cá nhân, cơ sở, quốc gia, khu vực và quốc tế” (Xem mục 2 của Phần I. Mục tiêu và các mục đích của Khuyến nghị). Tài liệu này định nghĩa dữ liệu nghiên cứu mở như sau (Xem mục 7b của Phần II. Định nghĩa Khoa học Mở):
“Dữ liệu nghiên cứu mở bao gồm, trong số những điều khác, dữ liệu dạng số và tuần tự, cả thô và đã được xử lý, và siêu dữ liệu kèm theo, cũng như các điểm số, các hồ sơ văn bản, các hình ảnh và âm thanh, các giao thức, mã phân tích và tiến trình có thể được mở cho bất kỳ ai để sử dụng, sử dụng lại, giữ lại và phân phối lại, tuân thủ thừa nhận ghi công. Dữ liệu nghiên cứu mở là sẵn sàng ở định dạng kịp thời và thân thiện với người sử dụng, người và máy đọc được và hành động được, phù hợp với các nguyên tắc của điều hành và quản trị dữ liệu tốt, ấy là các nguyên tắc Tìm thấy được, Truy cập được, Tương hợp được, Sử dụng lại được – FAIR (Findable, Accessible, Interoperable, Reusable), được sự giám tuyển và duy trì thường xuyên hỗ trợ.”
Cũng cần bổ sung thêm rằng ‘Dữ liệu nghiên cứu mở’ là một trong năm thành phần của ‘Kiến thức khoa học mở’, nên nó cũng mang các đặc tính của ‘Kiến thức khoa học mở’, được định nghĩa như sau (Xem mục 7 của Phần II. Định nghĩa Khoa học Mở):
“Kiến thức khoa học mở tham chiếu tới việc truy cập mở tới các xuất bản phẩm khoa học, dữ liệu nghiên cứu, siêu dữ liệu, tài nguyên giáo dục mở, phần mềm và mã nguồn và phần cứng mà chúng sẵn sàng trong phạm vi công cộng hoặc có bản quyền và được cấp phép theo một giấy phép mở cho phép truy cập, sử dụng lại, tái mục đích, tùy chỉnh và phân phối theo các điều kiện nhất định, được cung cấp cho tất cả các tác nhân ngay lập tức hoặc nhanh nhất có thể,... và miễn phí.”
2. FAIR là gì?
Như được nêu ở trên, FAIR là các ký tự đầu của các từ tiếng Anh gồm Findable, Accessible, Interoperable, Reusable, có nghĩa là Tìm thấy được, Truy cập được, Tương hợp được, và Sử dụng lại được.
Theo FORCE11[2], một cộng đồng gồm các học giả, thủ thư, nhân viên lưu trữ, nhà xuất bản và nhà cấp vốn nghiên cứu được thành lập để giúp tạo điều kiện cho sự thay đổi hướng tới cải thiện việc tạo lập và chia sẻ kiến thức, biến đổi truyền thông học thuật truyền thống trở nên hiện đại, phù hợp với kỷ nguyên số thông qua việc sử dụng hiệu quả công nghệ thông tin, đã đưa ra chỉ dẫn các nguyên tắc xuất bản dữ liệu theo FAIR như sau[3]:
“Một trong những thách thức của khoa học tăng cường dữ liệu là tạo thuận lợi để phát hiện tri thức bằng việc hỗ trợ cho con người và máy nhằm phát hiện, truy cập tới, tích hợp và phân tích, thực hiện các tác vụ đúng thích hợp đối với dữ liệu khoa học và liên kết tới các thuật toán và tiến trình công việc của chúng. Vì vậy dữ liệu, bao gồm cả siêu dữ liệu khoa học, cần phải là Tìm thấy được, Truy cập được, Tương hợp được và Sử dụng lại được”.
Để tìm thấy được (Findable):
F1: (siêu) dữ liệu chỉ định một mã thường trực toàn cầu duy nhất và vĩnh viễn
F2: dữ liệu được mô tả với siêu dữ liệu phong phú (rich metadata).
F3: (siêu) dữ liệu được đăng ký hoặc được đánh chỉ mục trong tài nguyên có khả năng tìm kiếm được.
F4: siêu dữ liệu chỉ định mã dữ liệu.
Để Truy cập được (Accessible):
A1: (siêu) dữ liệu có khả năng truy xuất được bằng mã của chúng khi sử dụng giao thức truyền thông được tiêu chuẩn hóa.
A1.1: giao thức đó là mở, tự do, và triển khai được vạn năng.
A1.2: giao thức đó cho phép thủ tục xác thực và ủy quyền, ở các nơi cần thiết.
A2: siêu dữ liệu là truy cập được, thậm chí khi dữ liệu không còn tồn tại nữa.
Để có khả năng tương hợp được (Interoperable):
I1: (siêu) dữ liệu sử dụng ngôn ngữ chính thống, truy cập được, được chia sẻ và áp dụng được rộng rãi để trình bày tri thức.
I2: (siêu) dữ liệu sử dụng các từ vựng tuân theo các nguyên tắc FAIR.
I3. (siêu) dữ liệu gồm các tham chiếu đủ điều kiện tới (siêu) dữ liệu khác.
Để sử dụng lại được (Re-usable):
R1: (siêu) dữ liệu có nhiều thuộc tính chính xác và thích hợp.
R1.1: (siêu) dữ liệu được phát hành với giấy phép sử dụng dữ liệu rõ ràng và truy cập được.
R1.2: (siêu) dữ liệu có liên kết tới nguồn gốc xuất xứ của chúng.
R1.3: (siêu) dữ liệu đáp ứng được các tiêu chuẩn cộng đồng phù hợp lĩnh vực.
Không chỉ dừng lại ở việc liệt kê các thành tố của từng trong số các nguyên tắc FAIR, FORCE11 còn đưa ra ‘Chỉ dẫn các nguyên tắc xuất bản dữ liệu để Tìm thấy được, Truy cập được, Tương hợp được và Sử dụng lại được phiên bản b1.0’[4], chi tiết hóa rất nhiều các công việc cần phải làm để (siêu) dữ liệu khoa học đáp ứng được FAIR.
Điều có thể sơ bộ rút ra được từ các nguyên tắc FAIR và chỉ dẫn của FORCE11 về các nguyên tắc đó cho thấy để (siêu) dữ liệu khoa học và nghiên cứu đạt được FAIR là rất không dễ, và một cách chủ quan có thể nói, ở thời điểm hiện tại, chưa ở đâu ở Việt Nam có (siêu) dữ liệu FAIR.
3. Mối quan hệ giữa Dữ liệu FAIR và Dữ liệu Mở
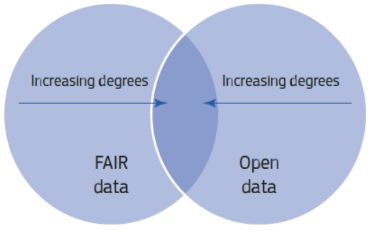
Như ở phần trên đã nêu, tài liệu Khuyến nghị Khoa học Mở của UNESCO 2021 định nghĩa ‘Dữ liệu nghiên cứu mở’ là phù hợp với FAIR, mặc dù trong thực tế “Dữ liệu có thể là FAIR hoặc Mở, vừa là FAIR vừa là Mở, hoặc không là FAIR không là Mở. Các lợi ích lớn nhất khi dữ liệu vừa là FAIR vừa là Mở, vì khi không có các hạn chế sẽ hỗ trợ được rộng lớn nhất có thể cho sử dụng lại, và sử dụng lại ở phạm vi rộng. Để tối đa hóa những lợi ích của việc biến dữ liệu FAIR thành hiện thực, và trong ngữ cảnh của các sáng kiến Khoa học Mở, các nguyên tắc FAIR nên được triển khai kết hợp với yêu cầu chính sách rằng dữ liệu nghiên cứu nên là Mở mặc định - đó là, Mở trừ phi có lý do tốt để hạn chế truy cập hoặc sử dụng lại”[5]. Nói một cách khác, mức độ FAIR của dữ liệu càng gia tăng, thì mức độ tính mở sẽ càng cao, và ngược lại, như trên Hình 1.
Hình 1. Mối quan hệ giữa dữ liệu FAIR và dữ liệu Mở
Tài liệu ‘Chi phí của việc không có dữ liệu nghiên cứu FAIR - Phân tích chi phí - lợi ích đối với dữ liệu nghiên cứu FAIR’[6] có đoạn: “Dữ liệu sẽ không thực sự sử dụng lại được trừ phi nó là MỞ, nghĩa là, sẵn sàng theo một giấy phép mở và với các chi phí tượng trưng (trong hầu hết các trường hợp chi phí bằng 0), và tính mở thường đi cùng với sự triển khai các nguyên tắc FAIR”. Lưu ý này là hoàn toàn phù hợp với định nghĩa ‘Dữ liệu nghiên cứu mở’ của UNESCO được nêu ở trên.
4. Chi phí của việc không có dữ liệu FAIR
Tài liệu ‘Chi phí của việc không có dữ liệu nghiên cứu FAIR…’ vừa được nêu ở trên đã tiến hành phân tích chi phí - lợi ích của việc không có dữ liệu nghiên cứu FAIR ở 28 quốc gia thuộc Liên minh châu Âu vào thời điểm trước năm 2018 với mục đích định tính và định lượng được các chi phí của việc không có dữ liệu nghiên cứu FAIR lên các hoạt động nghiên cứu, cộng tác và đổi mới sáng tạo để từ đó xúc tác cho các nhà hoạch định chính sách đưa ra các quyết định dựa vào bằng chứng về các cách thức hiệu quả để hỗ trợ cho triển khai các nguyên tắc dữ liệu FAIR vào đời sống thực tế ở châu Âu. Bảy chỉ số đó là: (1) thời gian bỏ ra - thời gian bị lãng phí, (2) chi phí lưu trữ, (3) chi phí cấp phép, (4) rút lại nghiên cứu, (5) cấp vốn hai lần, (6) liên ngành, và (7) tăng trưởng kinh tế tiềm năng.
Tài liệu đưa ra kết luận rằng chi phí thường niên của việc không có dữ liệu nghiên cứu FAIR khiến nền kinh tế châu Âu phải trả giá ít nhất 10.2 tỷ € mỗi năm. Ngoài ra, một số hệ lụy khác từ việc không có dữ liệu nghiên cứu FAIR nhưng không thể ước tính được chính xác, ví dụ như tác động lên chất lượng nghiên cứu, doanh thu của nền kinh tế, hoặc khả năng máy đọc được các dữ liệu nghiên cứu, có thể khiến nền kinh tế châu Âu phải trả thêm 16,9 tỷ € hàng năm ngoài những gì được ước tính qua các chỉ số trên.
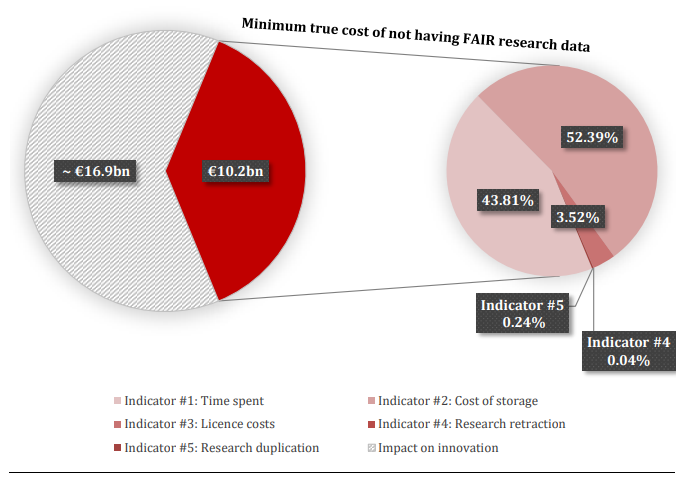
Hình 2. Phân bổ chi phí của việc không có dữ liệu nghiên cứu FAIR
Như Hình 2 chỉ ra, trong số bảy chỉ số trên, hai chỉ số đầu, chi phí lưu trữ và thời gian bỏ ra - thời gian bị lãng phí, có tác động mạnh nhất trong phân bổ chi phí của việc không có dữ liệu nghiên cứu FAIR, chúng lần lượt là 5,3 tỷ € (52,39%) và 4,5 € tỷ (43,81%) trong tổng số chi phí 10,2 tỷ € mỗi năm, tiếp theo sau là chỉ số chi phí cấp phép với 360 triệu € (3,52%). Các chỉ số còn lại có tác động không đáng kể.
Chỉ số chi phí lưu trữ là cao nhất được giải nghĩa bằng nhiều lý do (xem tài liệu [6], Bảng 3. Tính toán chỉ số #2: Chi phí lưu trữ), trong số đó có lý do chi phí gia tăng khi dữ liệu cùng một lúc được lưu trữ một cách không cần thiết ở nhiều kho lưu trữ (sao lưu được thực hiện như một phần của việc vận hành một hạ tầng hoặc một kho lưu trữ không được coi là các bản sao tách biệt khỏi dữ liệu) và khả năng giảm được số lượng các kho lưu trữ cần thiết và không bị đúp bản khi dữ liệu nghiên cứu là FAIR.
Một cách ngoại suy, chắc chắn việc không có dữ liệu nghiên cứu FAIR sẽ khiến nền kinh tế Việt Nam phải trả giá đáng kể, dù chủ quan cho rằng, chưa có bất kỳ nghiên cứu nào đánh giá chi phí của việc không có dữ liệu nghiên cứu FAIR ở Việt Nam.
5. Ví dụ về các thư viện áp dụng các nguyên tắc dữ liệu FAIR
Hiệp hội Thư viện Nghiên cứu châu Âu - LIBER (Ligue des Bibliothèques Européennes de Recherche - Association of European Research Libraries), tổ chức với hơn 420 thư viện nghiên cứu ở 40 quốc gia châu Âu[7], đã xuất bản tài liệu hướng dẫn ‘Triển khai các nguyên tắc dữ liệu FAIR: Vai trò của các thư viện’[8], trong đó minh họa một cách ngắn gọn FAIR là gì cho các thư viện, như trên Hình 3.
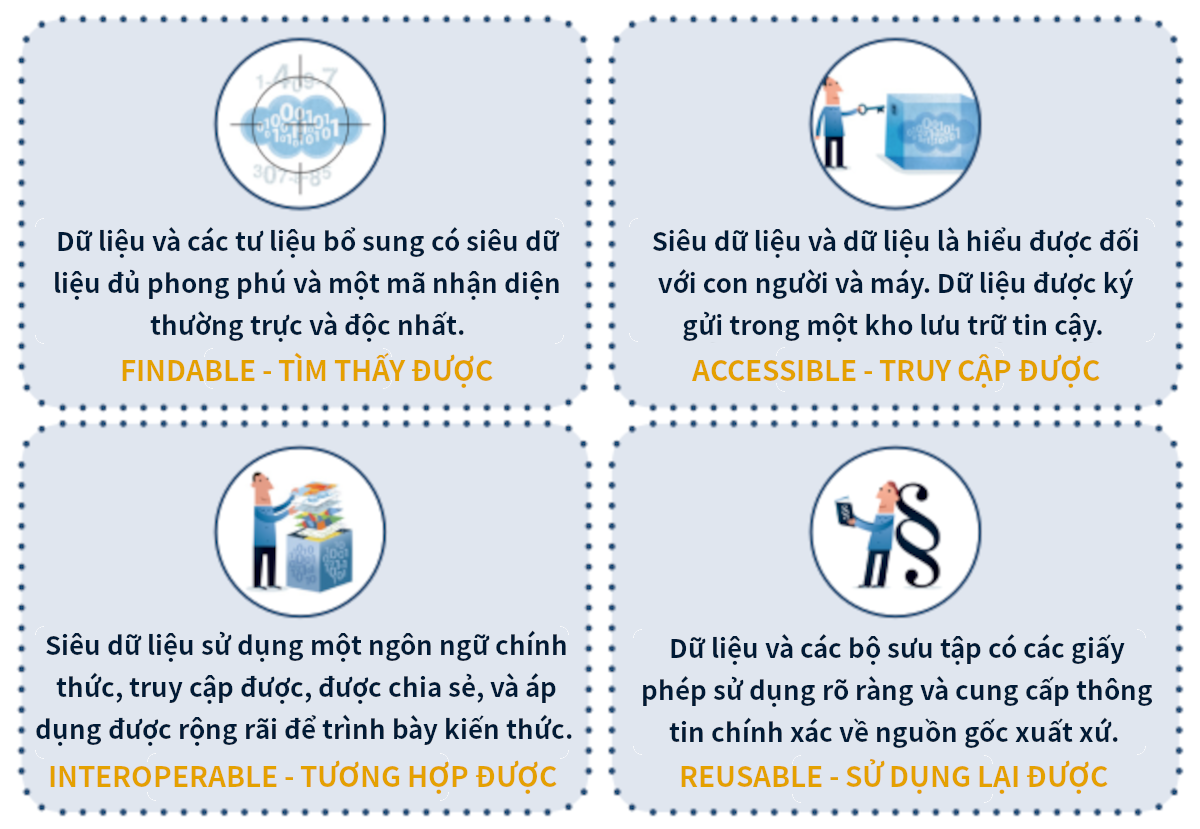
Hình 3. FAIR là gì?
Giải thích về tầm quan trọng của các nguyên tắc dữ liệu FAIR trong bối cảnh Khoa học Mở là một xu thế không thể đảo ngược của thế giới ngày nay, tài liệu nêu rằng:
“Sự tiến bộ của khoa học kỹ thuật số phát triển mạnh nhờ việc chia sẻ và khả năng tiếp cận dữ liệu kỹ thuật số kịp thời. Tương tự, nhu cầu về phát triển các hạ tầng và dịch vụ xúc tác cho sự thay đổi có hệ thống các thực hành khoa học hướng tới Khoa học Mở bây giờ được cả các tổ chức nghiên cứu và cấp vốn nghiên cứu ủng hộ mạnh mẽ. Các nguyên tắc FAIR tăng cường cho các phát triển đó”
và cho biết một dự án thí điểm trong chương trình Horizon 2020 của Ủy ban châu Âu giai đoạn 2014-2020 đã từng áp dụng các nguyên tắc dữ liệu FAIR:
“Trong Thí điểm Dữ liệu Nghiên cứu Mở của Ủy ban châu Âu (European Commission’s Open Research Data Pilot), các nguyên tắc FAIR được áp dụng để khuyến khích các nhà nghiên cứu được cấp vốn đảm bảo rằng dữ liệu của họ được quản lý tốt và sau đó được chia sẻ”.
Quan trọng hơn, tài liệu đã đưa ra các hướng dẫn cho các thư viện để bắt đầu đưa các nguyên tắc dữ liệu nghiên cứu FAIR vào thực tế cuộc sống bằng các hoạt động cụ thể sau đây:
Thúc đẩy các nguyên tắc FAIR cho các cán bộ nghiên cứu và công nghệ thông tin bản địa;
Kết hợp các nguyên tắc FAIR vào Kế hoạch Quản lý Dữ liệu của bạn và các thực hành cũng như các chính sách bảo tồn dữ liệu kỹ thuật số của bạn;
Tìm kiếm các cơ hội để giám tuyển, làm phong phú, nắm bắt và bảo tồn dữ liệu nghiên cứu sẽ giúp tạo ra dữ liệu tìm thấy được, truy cập được, tương hợp được và sử dụng lại được. Các điểm khởi đầu tốt là các bộ sưu tập của các nhà nghiên cứu riêng lẻ, hoặc một bộ sưu tập dữ liệu của một nhóm nghiên cứu;
Đào tạo cho các thủ thư làm việc theo chủ đề và dữ liệu về siêu dữ liệu, các từ vựng và công cụ chuyên ngành để làm cho dữ liệu thành FAIR;
Khuyến khích các nhà nghiên cứu ký gửi dữ liệu với các kho lưu trữ áp dụng các nguyên tắc FAIR;
Đánh giá các bộ sưu tập dữ liệu và các thực hành quản lý dữ liệu ở cơ sở của bạn theo các nguyên tắc FAIR.
Các thư viện thành viên của LIBER cũng được sự ủng hộ từ Ủy ban châu Âu trong việc áp dụng các nguyên tắc dữ liệu FAIR, bằng chứng là vào tháng 7/2016, Chương trình Horizon 2020 của Liên minh châu Âu đã xuất bản tài liệu ‘Hướng dẫn quản lý dữ liệu FAIR trong Horizon 2020’[9] phiên bản 3.0.
Trên thực tế, dù các nguyên tắc dữ liệu FAIR còn khá mới khi chúng được nhắc tới trong các tài liệu từ 2016, ngày càng nhiều thư viện nghiên cứu và học thuật đang làm quen với các nguyên tắc này và một số thư viện ở châu Âu và nước Mỹ, đã xác nhận và áp dụng chúng. “Ví dụ, Thư viện Đại học Columbia (Mỹ), Thư viện trực tuyến Đại học Maastricht (Hà Lan), Thư viện Đại học Stavanger (Na Uy), Thư viện Đại học Cambridge (Anh), Thư viện Đại học Kent (Anh), Thư viện Merced Đại học California (Mỹ) có xác nhận và đã áp dụng các nguyên tắc FAIR trong hoạt động của họ”, như được nêu trong một tài liệu nghiên cứu[10] được xuất bản tháng 12/2021.
Không chỉ các thư viện đại học áp dụng các nguyên tắc dữ liệu FAIR, mà còn cả một số cơ sở di sản văn hóa trong phong trào OpenGLAM (với GLAM là ký tự đầu trong tiếng Anh của Galleries, Libraries, Archives, Museums, lần lượt có nghĩa trong tiến Việt là các Phòng trưng bày, Thư viện, Kho lưu trữ, Viện bảo tàng) cũng hưởng ứng nhiệt tình, ví dụ điển hình nhất có lẽ là Europeana, một cơ sở di sản văn hóa của châu Âu nổi tiếng khắp trên thế giới, nơi có hơn 50 triệu tài nguyên kỹ thuật số được cung cấp từ hơn 3.700 cơ sở di sản văn hóa khắp châu Âu có kết nối liên thông với nó, cũng đã và đang triển khai các dịch vụ của nó tuân thủ các nguyên tắc dữ liệu FAIR[11]. Hơn nữa, Liên minh châu Âu đã và đang áp dụng các nguyên tắc dữ liệu FAIR để hướng dẫn cho việc thiết kế và triển khai các sáng kiến chủ chốt như Đám mây Khoa học Mở châu Âu - EOSC (European Open Science Cloud, khởi xướng ngày 26/10/2017) như được minh họa bằng dự án FAIRsFAIR dài 36 tháng kể từ ngày 01/03/2019.
6. Kết luận và gợi ý
Cách mạng công nghiệp lần thứ tư cho thấy dữ liệu là tối quan trọng cho nhiều công nghệ đương đại như trí tuệ nhân tạo, dữ liệu lớn hoặc Internet của vạn vật. Tuy nhiên, dữ liệu sẽ chỉ có ý nghĩa, bên cạnh những điều khác, khi chúng không phải là các đúp bản của dữ liệu gốc ban đầu, và phải tuân thủ các tiêu chuẩn tốt về quản lý và quản trị dữ liệu như các nguyên tắc dữ liệu FAIR.
Khoa học Mở, một xu thế không thể đảo ngược ngày nay, đã và đang được UNESCO dẫn dắt triển khai ở các mức quốc tế, khu vực, quốc gia, cơ sở, bao gồm các hội/hiệp hội/tổ chức/cơ sở thư viện giáo dục đại học, cũng khuyến nghị áp dụng các nguyên tắc dữ liệu FAIR cho dữ liệu nghiên cứu mở, đặc biệt khi xây dựng các hạ tầng và dịch vụ khoa học mở[12], điều mà các thư viện đại học luôn nằm ở tuyến đầu.
Để tuân thủ các nguyên tắc dữ liệu FAIR là không dễ, đòi hỏi phải tuân thủ hàng loạt các tiêu chuẩn cho cả dữ liệu, siêu dữ liệu, và dữ liệu mở liên kết, ví dụ như những gì cơ sở di sản văn hóa Europeana đã và đang áp dụng, bao gồm cả giao thức thu thập siêu dữ liệu của sáng kiến lưu trữ mở OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting), và với 14 tuyên bố quyền của Europeana[13], bao gồm cả các quyền tương ứng với một loạt các giấy phép mở Creative Commons (6 giấy phép tiêu chuẩn và 2 công cụ dành cho phạm vi công cộng - Public Domain) cũng như các quyền truy cập đóng thường đi với cái gọi là quản lý các quyền số - DRM (Digital Right Management) là một ví dụ điển hình mà các hệ thống thư viện liên thông của Việt Nam rất nên tham khảo, để có thể đáp ứng mọi yêu cầu, bất kể mức độ “Đóng” hay “Mở” nào được các tác giả hay cơ sở giáo dục và/hoặc các thư viện của chúng muốn gắn cho các tài nguyên họ sở hữu được kết nối và/hoặc đặt chỗ trên hệ thống liên thông đó.
Đối với các hội/hiệp hội/tổ chức/cơ sở thư viện giáo dục đại học và các bên liên quan, để bắt đầu làm quen và/hoặc triển khai các bước đi đầu tiên với các nguyên tắc dữ liệu FAIR, gợi ý, ngoài vô số các tài liệu liên quan khác, có thể tham khảo các tài liệu được tham chiếu tới trong bài viết này, đặc biệt là tài liệu ‘Hướng dẫn quản lý dữ liệu FAIR trong Horizon 2020’[9], phần trả lời cho một loạt các câu hỏi để đáp ứng FAIR cho các xuất bản phẩm và dữ liệu, với hàng loạt các câu hỏi cho từng thành phần của FAIR. Ở mức đơn giản nhất, có thể kiểm tra nhanh “Dữ liệu của bạn có là FAIR” với tài liệu của các tác giả từ EUDAT chỉ dài một trang[14], trong khi ở mức toàn diện và phức tạp hơn nhiều, có thể tham khảo tài liệu hướng dẫn của dự án FAIRsFAIR “D3.4 Khuyến nghị thực hành để hỗ trợ các nguyên tắc dữ liệu FAIR”[15].
Còn đối với cá nhân các nhà nghiên cứu và/hoặc cán bộ thủ thư, để bắt đầu đi với FAIR cùng Khoa học Mở, ngoài vô số các cách thức khác, gợi ý có thể đi theo ‘Hướng dẫn lộ trình Khoa học Mở cho bạn’[16] trong chương trình ‘Chuyển đổi sang Khoa học Mở’ - TOPS (Transform to Open Science) mà Cơ quan Hàng không Vũ trụ Mỹ (NASA) đã phát động trong năm ‘2023 - Năm Khoa học Mở’, để bản thân mình có được, ít nhất, ‘Các kỹ năng Khoa học Mở Cốt lõi’, gồm: (1) Biết cách sử dụng ORCID, Zenodo và GitHub; (2) Biết cách chỉ định một mã nhận diện đối tượng số – DOI (Digital Object Identifier); (3) Biết cách áp dụng một giấy phép đúng; (4) Biết cách lập kế hoạch quản lý dữ liệu và phần mềm; (5) Biết cách tìm ra các kho phần mềm cộng đồng; và (6) Biết cách tổ chức các cuộc họp mở.
Tài liệu tham khảo
[1] UNESCO, 2021: Recommendation on Open Science: https://unesdoc.unesco.org/ark:/48223/pf0000379949. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/l3q04t99nil5mgo/379949eng_Vi-25112021.pdf?dl=0
[2] FORCE11: About FORCE11: https://force11.org/info/about-force11/
[3] FORCE11: The FAIR Data Principles: https://www.force11.org/group/fairgroup/fairprinciples. Bản dịch sang tiếng Việt: https://vnfoss.blogspot.com/2017/07/cac-nguyen-tac-du-lieu-fair.html
[4] FORCE11: Guiding Principles for Findable, Accessible, Interoperable and Re-usable Data Publishing version b1.0: https://force11.org/info/guiding-principles-for-findable-accessible-interoperable-and-re-usable-data-publishing-version-b1-0/. Bản dịch sang tiếng Việt: https://vnfoss.blogspot.com/2017/07/chi-dan-cac-nguyen-tac-xuat-ban-du-lieu.html
[5] European Commission, 2018: Turning FAIR into Reality - Final Report and Action Plan from the European Commission Expert Group on FAIR Data: https://op.europa.eu/en/publication-detail/-/publication/7769a148-f1f6-11e8-9982-01aa75ed71a1/language-en/format-PDF/source-80611283. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/wtiraui8svilgei/turning_fair_into_reality_1-Vi-30042019.pdf?dl=0, phần 2.3 FAIR và dữ liệu mở, tr. 34-35.
[6] European Commission, 2018: Cost of not having FAIR research data. Cost-Benefit analysis for FAIR research data: http://publications.europa.eu/resource/cellar/d375368c-1a0a-11e9-8d04-01aa75ed71a1.0001.01/DOC_1. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/10kblenwlhca1jx/Cost-of-not-having-FAIR-research-data_Vi-02042023.pdf?dl=0
[7] LIBER: LIBER Participants: https://libereurope.eu/liber-participants/
[8] LIBER: Implementing FAIR Data Principles: The Role of Libraries: https://libereurope.eu/wp-content/uploads/2020/09/LIBER-FAIR-Data.pdf. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/c2qtw41dxdnsgq3/LIBER-FAIR-Data_Vi-15042023.pdf?dl=0
[9] H2020 Programme, EC, 2016: Guidelines on FAIR Data Management in Horizon 2020: https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/aitpozpizie2iv2/h2020-hi-oa-data-mgt_en_Vi-17042023.pdf?dl=0
[10] Liah Shonhe, Priti Jain: Adoption of FAIR Data Principles in Academic Libraries: Lessons from Practices of Some Universities in Europe and America: http://arcis.ui.edu.ng/jisst/upload/v5n3/JISST-5%5B3%5D1-17-LSONHE-JAIN-Adoption%20of%20FAIR%20Data%20Principles%20in%20Academic%20Libraries-Lessons%20from%20Practices%20of%20Some%20University%20Libraries%20in%20Europe%20and%20America.pdf, see a part on ‘Adoption and Enactments of Fair Data Principles in Academic Libraries’.
[11] Europeana pro: Europeana and the FAIR principles for research data: https://pro.europeana.eu/post/europeana-and-the-fair-principles-for-research-data. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/du-lieu-mo/europeana-va-cac-nguyen-tac-fair-cho-du-lieu-nghien-cuu-915.htm
[12] UNESCO, 2022: UNESCO Open Science Toolkit – Guidance: Bolstering Open Science Infrastructures for All: https://unesdoc.unesco.org/ark:/48223/pf0000383711. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/csrj5bjua4h007s/383711eng_Vi-25012023.pdf?dl=0, xem phần ‘Các đầu tư nào nên được làm để nuôi dưỡng các hạ tầng khoa học mở?’, mục ‘1 Hạ tầng cốt lõi’
[13] Lê Trung Nghĩa, 2021: Công nghệ mở trong các cơ sở văn hóa và giáo dục: https://giaoducmo.avnuc.vn/bai-viet-toan-van/cong-nghe-mo-trong-cac-co-so-van-hoa-va-giao-duc-513.html, xem phần ‘14 tuyên bố quyền đối với các đối tượng số của Europeana’
[14] Sarah Jones & Marjan Grootveld, EUDAT: How FAIR are your data?: https://zenodo.org/record/1065991. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/lzafy5dow3mll5o/How-FAIR-are-your-data_Vi-20042023.pdf?dl=0
[15] FAIRsFAIR, 30/06/2020: D3.4 Recommendations on practice to support FAIR data principles: https://doi.org/10.5281/zenodo.3924131. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/j7512lusvd5nzt7/D3.4_FAIRsFAIR_Recommendations_on_practice_to_support_FAIR_data_principles_20200603_v1.0_Vi-23042023.pdf?dl=0
[16] NASA: Guide for Your Open Science Journey: https://nasa.github.io/Transform-to-Open-Science-Book/Open_Science_Cookbook/Your_Open_Science_Journey.html. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/khoa-hoc-mo/huong-dan-lo-trinh-khoa-hoc-mo-cho-ban-888.html
![]()
Giấy phép nội dung: CC BY-SA Quốc tế
 Lê Trung Nghĩa
Lê Trung Nghĩa * Bài viết cho hội thảo ‘Xây dựng Trung tâm Tri thức số và mô hình thư viện đại học thông minh’ do Liên chi hội thư viện đại học khu vực phía Bắc (NALA) tổ chức ngày 19/05/2023 tại Vinh.
* Bài viết cho hội thảo ‘Xây dựng Trung tâm Tri thức số và mô hình thư viện đại học thông minh’ do Liên chi hội thư viện đại học khu vực phía Bắc (NALA) tổ chức ngày 19/05/2023 tại Vinh.Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Trang Web này được thành lập theo Quyết định số 142/QĐ-HH do Chủ tịch Hiệp hội các trường đại học, cao đẳng Việt Nam – AVU&C (Association of Vietnam Universities and Colleges), GS.TS. Trần Hồng Quân ký ngày 16/09/2019, ngay trước thềm của Hội thảo ‘Xây dựng và khai thác tài nguyên giáo dục mở’ do 5...
 ‘Tuyên ngôn về giảng dạy và học tập trong thời đại AI tạo sinh: Quan điểm tập thể quan trọng để điều hướng tương lai tốt hơn’ - bản dịch sang tiếng Việt
‘Tuyên ngôn về giảng dạy và học tập trong thời đại AI tạo sinh: Quan điểm tập thể quan trọng để điều hướng tương lai tốt hơn’ - bản dịch sang tiếng Việt
 ‘Sử dụng trí tuệ nhân tạo để trao quyền cho việc triển khai OER và khuyến nghị OER của UNESCO’ - bản dịch sang tiếng Việt
‘Sử dụng trí tuệ nhân tạo để trao quyền cho việc triển khai OER và khuyến nghị OER của UNESCO’ - bản dịch sang tiếng Việt
 ‘AI tạo sinh, nội dung tổng hợp, Tài nguyên Giáo dục Mở (OER), và Thực hành Giáo dục Mở (OEP): Mặt trận mới trong bối cảnh của tính mở’ - bản dịch sang tiếng Việt
‘AI tạo sinh, nội dung tổng hợp, Tài nguyên Giáo dục Mở (OER), và Thực hành Giáo dục Mở (OEP): Mặt trận mới trong bối cảnh của tính mở’ - bản dịch sang tiếng Việt
 Viết là suy nghĩ: Nghịch lý của các mô hình ngôn ngữ lớn (LLM)
Viết là suy nghĩ: Nghịch lý của các mô hình ngôn ngữ lớn (LLM)
 Đặt tên cho mọi thứ thật khó: Từ OELM đến GOLE
Đặt tên cho mọi thứ thật khó: Từ OELM đến GOLE
 Nơi Giáo dục Mở Gặp AI Tạo sinh: OELM
Nơi Giáo dục Mở Gặp AI Tạo sinh: OELM
 Hội thảo ‘Xây dựng nhà trường số trên nền khung năng lực số’ tại TP. Quy Nhơn, 25/06/2025
Hội thảo ‘Xây dựng nhà trường số trên nền khung năng lực số’ tại TP. Quy Nhơn, 25/06/2025
 50 công cụ AI tốt nhất cho năm 2025 (Đã thử và kiểm nghiệm)
50 công cụ AI tốt nhất cho năm 2025 (Đã thử và kiểm nghiệm)
 Các bài toàn văn cho tới hết năm 2024
Các bài toàn văn cho tới hết năm 2024
 Các bài trình chiếu trong năm 2024
Các bài trình chiếu trong năm 2024
 Các lớp tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ tới hết năm 2024
Các lớp tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ tới hết năm 2024
 Các tài liệu dịch sang tiếng Việt tới hết năm 2024
Các tài liệu dịch sang tiếng Việt tới hết năm 2024
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2024
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2024
 Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
 Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
 Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
 ORCID - Quy trình làm việc
ORCID - Quy trình làm việc
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
 Năm Khoa học Mở & Chuyển đổi sang Khoa học Mở - Tổng hợp các bài liên quan
Năm Khoa học Mở & Chuyển đổi sang Khoa học Mở - Tổng hợp các bài liên quan
 ‘Bộ công cụ Khoa học Mở của UNESCO’ - Các bản dịch sang tiếng Việt
‘Bộ công cụ Khoa học Mở của UNESCO’ - Các bản dịch sang tiếng Việt
 Định nghĩa các khái niệm liên quan tới Khoa học Mở
Định nghĩa các khái niệm liên quan tới Khoa học Mở
 ‘Digcomp 2.2: Khung năng lực số cho công dân - với các ví dụ mới về kiến thức, kỹ năng và thái độ’, EC xuất bản năm 2022
‘Digcomp 2.2: Khung năng lực số cho công dân - với các ví dụ mới về kiến thức, kỹ năng và thái độ’, EC xuất bản năm 2022
 ‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
 Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu