Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
- Thứ hai - 17/11/2025 06:26
- In ra
- Đóng cửa sổ này

ReAct Prompting
Theo: https://www.promptingguide.ai/techniques/react
Yao và cộng sự, 2022 đã giới thiệu một khuôn khổ có tên ReAct, trong đó các mô hình ngôn ngữ lớn - LLM (Large Language Model) được sử dụng để tạo ra cả dấu vết suy luận và các hành động cụ thể theo nhiệm vụ một cách đan xen.
Việc tạo ra dấu vết suy luận cho phép mô hình tạo ra, theo dõi và cập nhật các kế hoạch hành động, và thậm chí xử lý các trường hợp ngoại lệ. Bước hành động này cho phép giao tiếp và thu thập thông tin từ các nguồn bên ngoài như cơ sở kiến thức hoặc môi trường.
Khuôn khổ ReAct có thể cho phép các LLM tương tác với các công cụ bên ngoài để thu thập thêm thông tin, dẫn đến các phản hồi đáng tin cậy và thực tế hơn.
Kết quả cho thấy ReAct có thể vượt trội hơn một số nền tảng tiên tiến về ngôn ngữ và các nhiệm vụ ra quyết định. ReAct cũng giúp cải thiện khả năng diễn giải và độ tin cậy của LLM đối với con người. Nhìn chung, các tác giả nhận thấy rằng phương pháp tiếp cận tốt nhất là sử dụng ReAct kết hợp với chuỗi tư duy - CoT (Chain-of-thought), cho phép sử dụng cả kiến thức nội bộ và thông tin bên ngoài thu được trong quá trình suy luận.
Cách thức hoạt động?
ReAct được lấy cảm hứng từ sự đồng vận giữa "hành động" và "lý luận", cho phép con người học các nhiệm vụ mới và đưa ra quyết định hoặc lý luận.
Phương pháp lời nhắc chuỗi tư duy (CoT) đã cho thấy khả năng của LLM trong việc thực hiện các dấu vết suy luận để tạo ra câu trả lời cho các câu hỏi liên quan đến số học và suy luận thông thường, cùng với các nhiệm vụ khác (Wei và cộng sự, 2022). Tuy nhiên, việc thiếu khả năng tiếp cận thế giới bên ngoài hoặc không thể cập nhật kiến thức có thể dẫn đến các vấn đề như ảo giác sự thật và lan truyền lỗi.
ReAct là một mô hình chung kết hợp suy luận và hành động với LLM. ReAct gợi ý cho LLM tạo ra các dấu vết lý luận bằng lời nói và hành động cho một nhiệm vụ. Điều này cho phép hệ thống thực hiện việc suy luận động để tạo lập, duy trì và điều chỉnh các kế hoạch hành động, đồng thời cho phép tương tác với môi trường bên ngoài (ví dụ: Wikipedia) để kết hợp thông tin bổ sung vào suy luận. Hình dưới đây minh họa một ví dụ về ReAct và các bước khác nhau liên quan để thực hiện trả lời câu hỏi.

Image Source: Yao et al., 2022
Trong ví dụ trên, chúng ta truyền một lời nhắc như câu hỏi sau đây từ HotpotQA:
Ngoài Apple Remote, còn có thiết bị nào khác có thể kiểm soát chương trình mà Apple Remote ban đầu được thiết kế để tương tác hay không? (Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?)
Lưu ý rằng các ví dụ trong ngữ cảnh đó cũng được thêm vào lời nhắc, nhưng chúng tôi loại trừ điều đó ở đây để đơn giản hóa. Chúng ta có thể thấy rằng mô hình tạo ra các quỹ đạo giải quyết nhiệm vụ (Suy nghĩ, Hành động). Quan sát tương ứng với quan sát từ môi trường đang được tương tác (ví dụ: Công cụ tìm kiếm). Về bản chất, ReAct có thể truy xuất thông tin để hỗ trợ suy luận, trong khi suy luận giúp xác định mục tiêu cần truy xuất tiếp theo.
Lời nhắc ReAct
Để minh họa cách thức hoạt động của lời nhắc ReAct, hãy xem xét một ví dụ từ bài báo.
Bước đầu tiên là chọn các trường hợp từ tập huấn luyện (ví dụ: HotPotQA) và tạo ra các quỹ đạo định dạng ReAct. Chúng được sử dụng như các ví dụ mẫu trong các lời nhắc. Các quỹ đạo bao gồm nhiều bước suy nghĩ-hành động-quan sát như được hiển thị trong hình trên. Các suy nghĩ dạng tự do được sử dụng để hoàn thành các nhiệm vụ khác nhau như phân tích câu hỏi, trích xuất thông tin, thực hiện suy luận thông thường/số học, hướng dẫn việc tìm kiếm và tổng hợp câu trả lời cuối cùng.
Sau đây là một ví dụ về hình thức của lời nhắc ReAct (lấy từ bài báo và rút gọn thành một ví dụ để đơn giản hơn):
Câu hỏi Phạm vi độ cao của khu vực mà phần phía đông của tạo núi Colorado kéo dài đến là bao nhiêu?Suy nghĩ 1 Tôi cần tìm kiếm tạo núi Colorado, tìm khu vực mà phần phía đông của tạo núi Colorado kéo dài đến, sau đó tìm phạm vi độ cao của khu vực đó.Hành động 1 Tìm kiếm [tạo núi Colorado]Quan sát 1 Tạo núi Colorado là một giai đoạn kiến tạo núi (tạo núi) ở Colorado và các khu vực xung quanh.Suy nghĩ 2 Nó không đề cập đến phần phía đông. Vì vậy, tôi cần tra cứu phần phía đông.Hành động 2 Tra cứu [phần phía đông]Quan sát 2 (Kết quả 1 / 1) Phần phía đông kéo dài đến Cao nguyên và được gọi là tạo núi Đồng bằng Trung tâm.Suy nghĩ 3 Phần phía đông của tạo núi Colorado kéo dài đến Cao nguyên. Vì vậy, tôi cần tìm kiếm Cao nguyên và tìm phạm vi độ cao của nó.Hành động 3 Tìm kiếm [Vùng Cao]Quan sát 3 Vùng Cao đề cập đến một trong hai vùng đất riêng biệtSuy nghĩ 4 Thay vào đó, tôi cần tìm kiếm Vùng Cao (Hoa Kỳ).Hành động 4 Tìm kiếm [Vùng Cao (Hoa Kỳ)]Quan sát 4 Vùng Cao là một tiểu vùng của Đại Bình nguyên. Từ đông sang tây, vùng Cao cao tăng dần độ cao từ khoảng 1.800 đến 7.000 ft (550 đến 2.130 m).[3]Suy nghĩ 5 Vùng Cao tăng dần độ cao từ khoảng 1.800 đến 7.000 ft, vì vậy đáp án là 1.800 đến 7.000 ft....
Lưu ý rằng các thiết lập lời nhắc khác nhau được sử dụng cho các loại nhiệm vụ khác nhau. Đối với các nhiệm vụ mà suy luận là yếu tố quan trọng hàng đầu (ví dụ: HotpotQA), nhiều bước suy nghĩ-hành động-quan sát được sử dụng cho lộ trình giải quyết nhiệm vụ. Đối với các nhiệm vụ ra quyết định bao gồm nhiều bước hành động, suy nghĩ được sử dụng ít hơn.

Video: Building a ReAct AI Agent (Tutorial)
Kết quả các nhiệm vụ chuyên sâu về kiến thức
Bài báo đầu tiên đánh giá ReAct trong các nhiệm vụ suy luận chuyên sâu về kiến thức như trả lời câu hỏi (HotPotQA) và xác minh sự thật (Fever). PaLM-540B được sử dụng làm mô hình cơ sở cho việc nhắc.
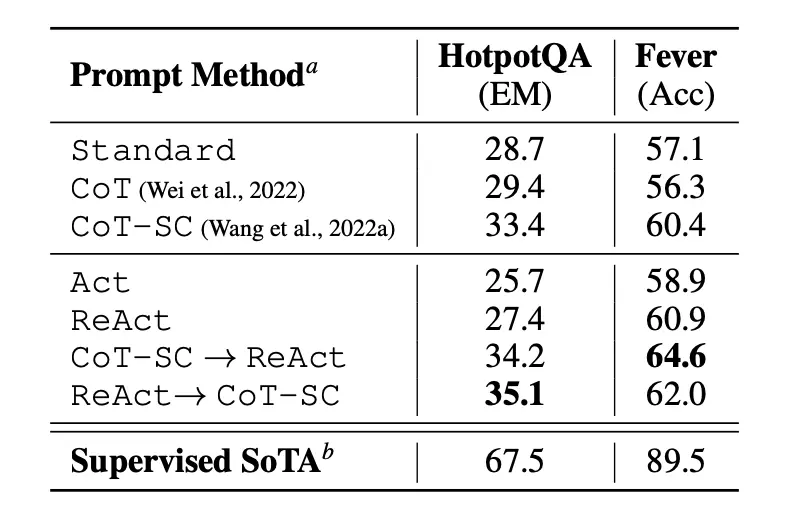
Image Source: Yao et al., 2022
Kết quả của lời nhắc trong HotPotQA và Fever khi sử dụng các phương pháp nhắc khác nhau cho thấy ReAct nhìn chung hoạt động tốt hơn Act (chỉ bao gồm hành động) ở cả hai nhiệm vụ.
Chúng ta cũng có thể thấy ReAct hoạt động tốt hơn CoT trên Fever và chậm hơn CoT trên HotpotQA. Bài báo đã cung cấp một phân tích lỗi chi tiết. Tóm lại:
-
CoT bị ảo giác thực tế
-
Ràng buộc về cấu trúc của ReAct làm giảm tính linh hoạt trong việc xây dựng các bước suy luận
-
ReAct phụ thuộc rất nhiều vào thông tin mà nó đang thu thập; kết quả tìm kiếm không cung cấp thông tin sẽ làm chệch hướng suy luận của mô hình và dẫn đến khó khăn trong việc khôi phục và định hình lại các ý tưởng.
Các phương pháp lời nhắc kết hợp và hỗ trợ chuyển đổi giữa ReAct và CoT + Tự nhất quán thường hoạt động tốt hơn tất cả các phương pháp lời nhắc khác.
Kết quả trong các Nhiệm vụ Ra quyết định
Bài báo cũng báo cáo các kết quả chứng minh hiệu suất của ReAct trong các nhiệm vụ ra quyết định. ReAct được đánh giá dựa trên hai tiêu chuẩn là ALFWorld (trò chơi dựa trên văn bản) và WebShop (môi trường trang web mua sắm trực tuyến). Cả hai đều liên quan đến các môi trường phức tạp đòi hỏi khả năng suy luận để hành động và khám phá hiệu quả.
Lưu ý rằng các lời nhắc ReAct được thiết kế khác nhau cho các nhiệm vụ này nhưng vẫn giữ nguyên ý tưởng cốt lõi là kết hợp suy luận và hành động. Dưới đây là một ví dụ về bài toán ALFWorld liên quan đến lời nhắc ReAct.
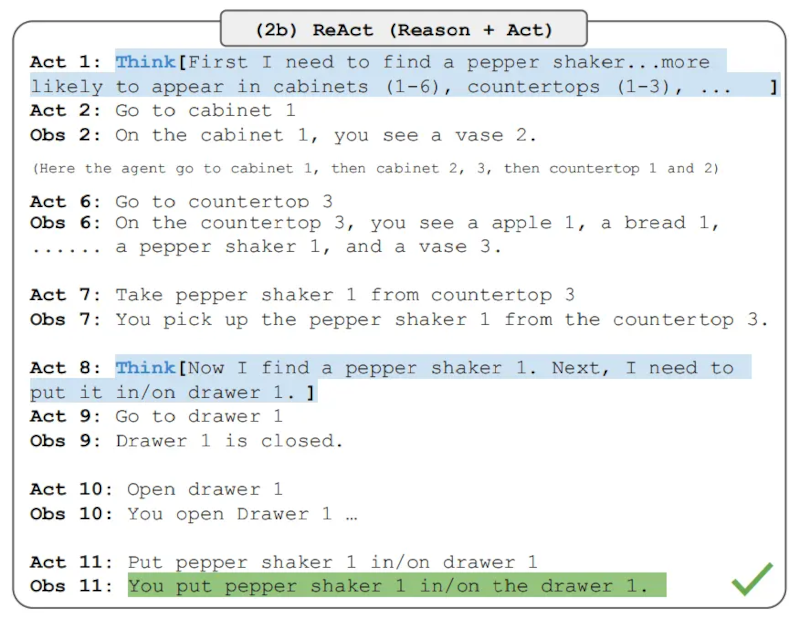
Image Source: Yao et al., 2022
ReAct vượt trội hơn Act trên cả ALFWorld và Webshop. Hành động, nếu không có tư duy, sẽ không thể phân tích chính xác các mục tiêu thành các mục tiêu con. Suy luận dường như có lợi thế trong ReAct cho các loại nhiệm vụ này, nhưng các phương pháp dựa trên lời nhắc hiện tại vẫn còn kém xa hiệu suất của con người chuyên nghiệp trong các nhiệm vụ này.
Xem bài báo để biết kết quả chi tiết hơn.
Sử dụng LangChain ReAct
Dưới đây là một ví dụ cụ thể về cách thức hoạt động của phương pháp gợi ý ReAct trong thực tế. Chúng tôi sẽ sử dụng OpenAI cho LLM và LangChain vì nó đã có sẵn chức năng tích hợp tận dụng khung ReAct để xây dựng các tác nhân thực hiện nhiệm vụ bằng cách kết hợp sức mạnh của LLM và các công cụ khác nhau.
Trước tiên, hãy cài đặt và nhập các thư viện cần thiết:
%%capture# cập nhật hoặc cài đặt các thư viện cần thiết!pip install --upgrade openai!pip install --upgrade langchain!pip install --upgrade python-dotenv!pip install google-search-results# Nhập khẩu các thư việnimport openaiimport osfrom langchain.llms import OpenAIfrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom dotenv import load_dotenvload_dotenv()# tải lên các khóa API; bạn sẽ cần lấy những khóa này nếu chưa cóos.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Bây giờ chúng ta có thể cấu hình LLM, các công cụ chúng ta sẽ sử dụng và tác nhân cho phép chúng ta tận dụng khung ReAct cùng với LLM và các công cụ. Lưu ý rằng chúng ta đang sử dụng API tìm kiếm để tìm kiếm thông tin bên ngoài và LLM như một công cụ toán học.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)tools = load_tools(["google-serper", "llm-math"], llm=llm)agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
Sau khi cấu hình xong, chúng ta có thể chạy tác nhân với truy vấn/lời nhắc mong muốn. Lưu ý rằng ở đây chúng ta không cần cung cấp các ví dụ ít ỏi như đã giải thích trong bài báo.
agent.run("Bạn trai của Olivia Wilde là ai? Tuổi hiện tại của anh ấy là bao nhiêu lũy thừa 0,23?")
Chuỗi thực hiện trông như sau:
> Nhập vào chuỗi AgentExecutor mới...Tôi cần tìm ra bạn trai của Olivia Wilde là ai và sau đó tính tuổi của anh ấy lũy thừa 0,23.Hành động: Tìm kiếmĐầu vào hành động: “bạn trai của Olivia Wilde"Quan sát thấy: Olivia Wilde bắt đầu hẹn hò với Harry Styles sau khi chấm dứt mối quan hệ kéo dài nhiều năm với Jason Sudeikis — xem dòng thời gian mối quan hệ của họ.Suy luận: Tôi cần tìm ra tuổi của Harry StylesHành động: Tìm kiếmĐầu vào hành động: “Tuổi của Harry Styles”Quan sát thấy: 29 tuổiSuy luận: Tôi cần tính 29 lũy thừa 0,23Hành động: Tính toánĐầu vào hành động:29^0.23Quan sát thấy: Đáp án:2.169459462491557Suy luận:Giờ tôi đã biết đáp án cuối cùng.Câu trả lời cuối cùng: Harry Styles, bạn trai của Olivia Wilde, 29 tuổi và tuổi của anh ấy lũy thừa 0,23 là 2,169459462491557.> Chuỗi đã hoàn thành.
Kết quả đầu ra chúng ta nhận được như sau:
"Harry Styles, bạn trai của Olivia Wilde, 29 tuổi và tuổi của anh ấy lũy thừa 0,23 là 2,169459462491557."
Chúng tôi đã điều chỉnh ví dụ từ tài liệu LangChain, vì vậy công lao thuộc về họ. Chúng tôi khuyến khích người học khám phá các cách kết hợp công cụ và nhiệm vụ khác nhau.
Bạn có thể tìm thấy sổ ghi chép cho mã này tại đây: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo