Giáo dục mở - tài nguyên giáo dục mở
Ứng dụng và phát triển
(Bài đăng trên Tạp chí Tia Sáng, số 9 năm 2022, xuất bản ngày 05/05/2022, các trang 34-37. Phiên bản điện tử có tại địa chỉ: https://drive.google.com/file/d/1gyVMQFwVVKdDyi-gWAkA5faqrGj3CNLw/view?usp=sharing hoặc https://tiasang.com.vn/doi-moi-sang-tao/du-lieu-ca-nhan-tro-thanh-du-lieu-mo/)
Quy định Bảo vệ Dữ liệu Chung - GDPR (General Data Protection Regulation) hiện được coi là “một trong những quy định toàn diện nhất làm việc với dữ liệu cá nhân, và làm thay đổi cách các tổ chức thu thập và sử dụng dữ liệu” trên toàn thế giới. GDPR lấy lại toàn bộ quyền sở hữu, sửa chữa, thu thập, xử lý…tất cả các dữ liệu cá nhân cho người dùng từ tay các công ty, tổ chức công nghệ. Điều này không khỏi khiến ta tự hỏi liệu dữ liệu cá nhân có khi nào có thể trở thành dữ liệu mở - sẵn sàng cho bất kỳ ai truy cập, sử dụng, và chia sẻ hay không [1]? Câu trả lời là có.
Một vài khái niệm
Không phải mọi dữ liệu cá nhân đều cần phải bảo mật tuyệt đối, không thể tiết lộ và chia sẻ cho cộng đồng. Để có thể làm việc được tốt với dữ liệu cá nhân, cần phải phân biệt rõ thế nào là dữ liệu cá nhân, dữ liệu nhạy cảm và dữ liệu riêng tư.
Dữ liệu cá nhân (Personal Data) được GDPR[2] định nghĩa là: “bất kì thông tin nào liên quan đến việc xác định hoặc có thể xác định một thể nhân (‘chủ thể dữ liệu’). Một thể nhân là một cá nhân cụ thể có thể được nhận dạng trực tiếp hoặc gián tiếp thông qua một mã định dạng chẳng hạn như tên, số căn cước công dân, dữ liệu về địa điểm, mã định danh số hoặc thông qua một hoặc vài yếu tố đặc thù khác về về thể chất, sinh lý, di truyền, tinh thần, kinh tế, văn hóa hoặc xã hội của cá nhân đó.”
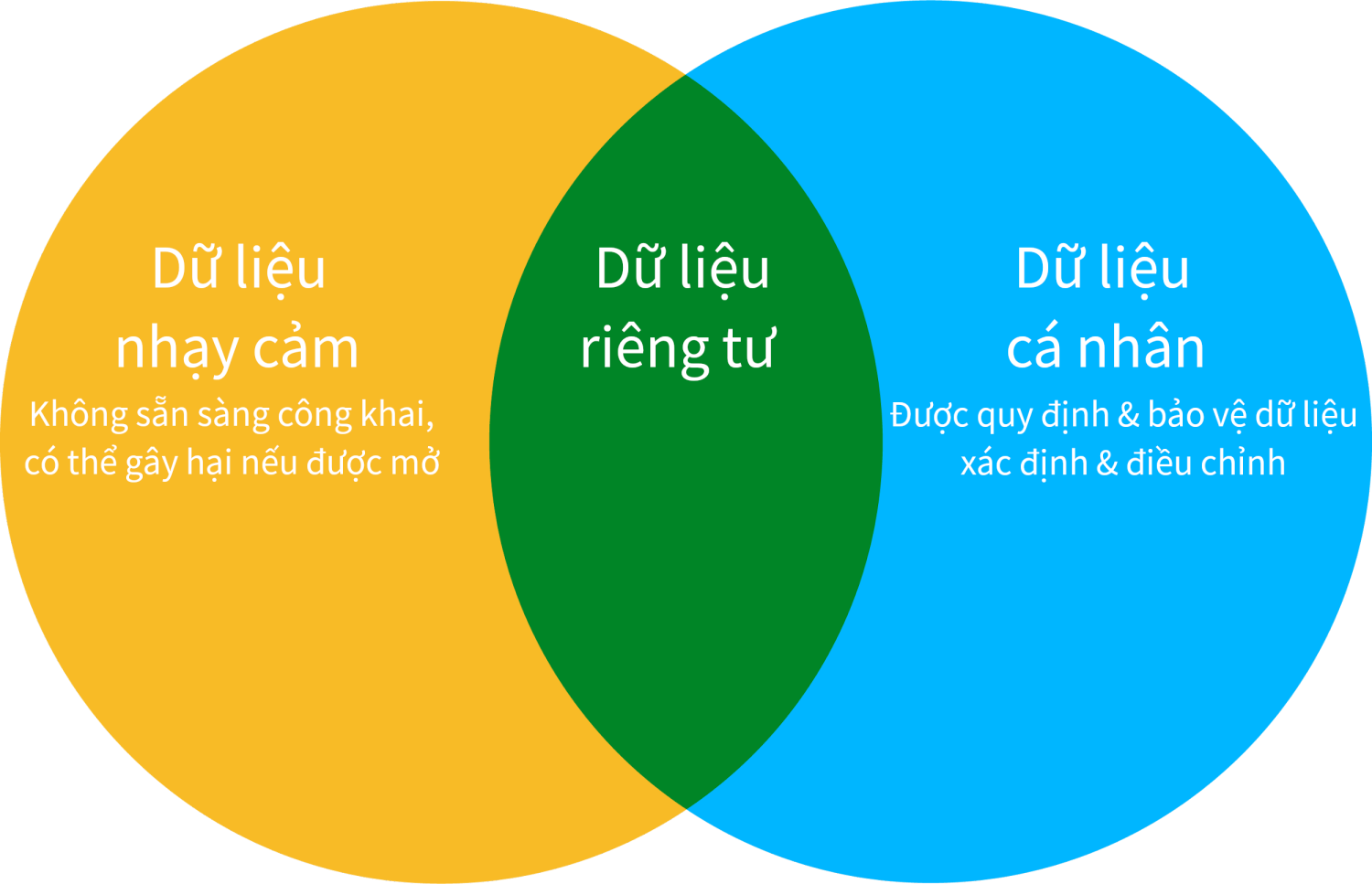
Hình 1. Quan hệ giữa dữ liệu cá nhân, dữ liệu nhạy cảm và dữ liệu riêng tư
Dữ liệu nhạy cảm (Sensitive Data): là dữ liệu có thông tin mật, thông tin lưu hành nội bộ của đơn vị hoặc do đơn vị quản lý, nếu lộ lọt ra ngoài sẽ gây ảnh hưởng xấu đến danh tiếng, tài chính và hoạt động của đơn vị[3].
Thông tin riêng tư (Private Information[4]): là thông tin liên quan tới một pháp nhân hoặc thể nhân có thể nhận dạng được; không là trong phạm vi công cộng hoặc kiến thức chung; và nếu để lộ có thể gây cho họ thiệt hại, tổn thất hoặc đau khổ cho họ. Định nghĩa này là rất giống với những gì GDPR gọi là dữ liệu danh mục đặc biệt[5].
Trước khi mở, dữ liệu cá nhân sẽ được xử lý thông qua quy trình ẩn danh cùng sự cân nhắc và lường trước các kẻ tấn công phát hiện các thông tin riêng tư giữa bể dữ liệu đã được ẩn danh. Theo đó:
Ẩn danh (Anonimisation) là quy trình sửa một tập hợp dữ liệu để làm giảm rủi ro tái nhận dạng nó càng nhiều càng tốt.
Kẻ tấn công (Adversary): Thực thể có khả năng truy cập tới một tập hợp dữ liệu được ẩn danh để tìm cách tái nhận dạng cá nhân hoặc để biết thêm thông tin về các cá nhân đó. Đối thủ không nhất thiết có ý định gây hại. Vì thế các quy trình ẩn danh được mô tả cũng bao trùm sự ngăn chặn mở ngẫu nhiên hoặc phát hiện thông tin riêng tư.
Một mặt, một khi dữ liệu vừa là dữ liệu cá nhân, vừa là dữ liệu nhạy cảm, thì nó được gọi là dữ liệu riêng tư của cá nhân. Mặt khác, một khi dữ liệu cá nhân được mở ra, hay còn được gọi là dữ liệu mở của cá nhân, thì nó không còn là dữ liệu nhạy cảm nữa, vì dữ liệu nhạy cảm, như định nghĩa của nó, là dữ liệu không sẵn sàng để mở công khai hay lộ lọt ra ngoài. Bởi vì, bất kì dữ liệu nhạy cảm hay riêng tư nào cũng có khả năng biên tập hoặc ẩn danh để có thể chia sẻ hoặc xa hơn nữa là mở.
Phổ của dữ liệu
Trên thực tế, không hiếm những quan điểm cứng nhắc về mở và chia sẻ dữ liệu cá nhân. Một phía cho rằng rằng dữ liệu cá nhân không bao giờ có thể là dữ liệu mở. Phía kia thì khẳng định dữ liệu mở không bao giờ gồm thông tin nhận dạng cá nhân. Thậm chí người ta còn cực đoan tới mức nghĩ rằng bất cứ dữ liệu nào bắt nguồn từ dữ liệu cá nhân, dù là khi nó được trải qua các bước ẩn danh (anonymised), được giả danh (pseudonymised) hoặc được tổng hợp (synthesised), đều không thể là dữ liệu mở. Nhưng điều đó hoàn toàn sai lầm.
Theo Hình 2 dưới đây về phổ dữ liệu của Viện Dữ liệu mở[6], trải dài từ dữ liệu đóng - Closed (chỉ trao đổi trong nội bộ tổ chức - Internal access), tới dữ liệu chia sẻ - Shared (lan truyền giữa các nhóm thỏa mãn một số điều kiện nhất định - Group-based access) và cao nhất là dữ liệu mở - Open (ai cũng có thể tiếp cận - Anyone). Ta có thể thấy một ví dụ về dữ liệu cá nhân vừa mang tính riêng tư vừa mang tính nhạy cảm đó là Hồ sơ y tế (Medical records) hoàn toàn có thể được ẩn danh hóa (Anonymisation) để trở thành dữ liệu chia sẻ, cho phép một số nhóm người nhất định truy cập như các nhà khoa học, y bác sĩ… để phục vụ mục đích nghiên cứu. Nếu được ẩn danh hóa sâu hơn, dữ liệu này còn có thể trở thành số liệu thống kê y tế (Health Statistics), được cấp phép mở (Open license), cho bất kì ai (Anyone) cũng có thể truy cập, chia sẻ, xử lý và phân tích.
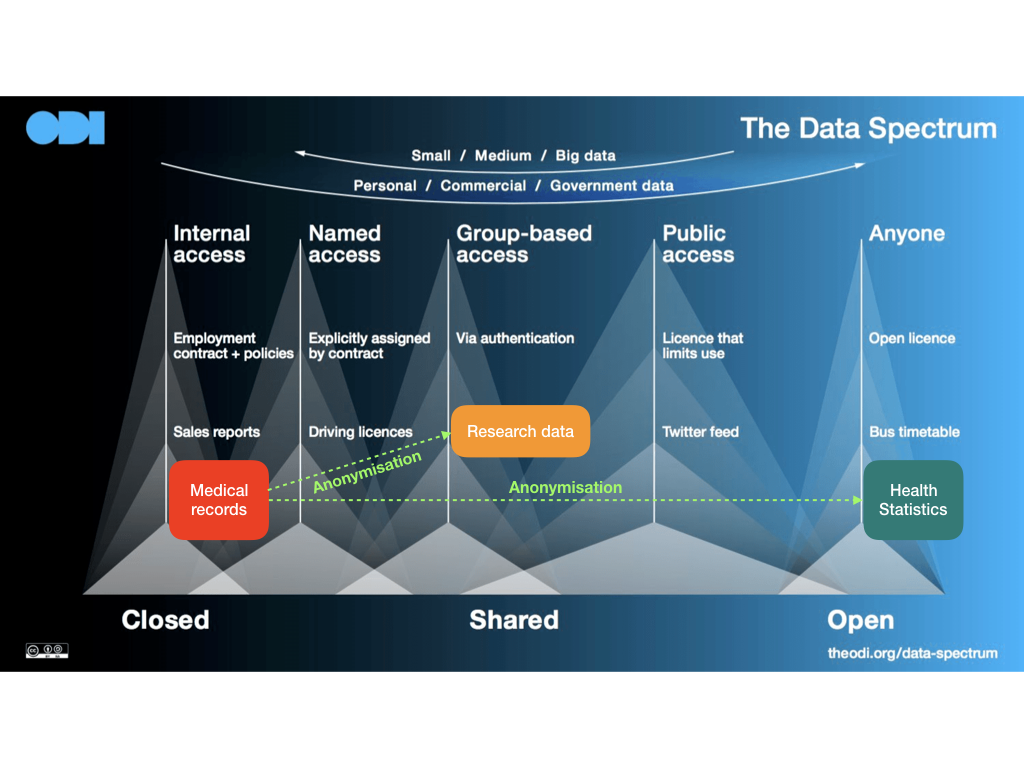
Hình 2. Phổ dữ liệu của Viện Dữ liệu Mở (ODI)
Dữ liệu về con người có thể là dữ liệu mở nếu điều đó có lợi cho xã hội. Ví dụ, hãy nghĩ về việc mở công khai dữ liệu về các tội phạm nguy hiểm cho xã hội, hay việc mở công khai dữ liệu về chi tiêu từ ngân sách của các đại biểu quốc hội được bầu. Nói một cách khác, khi bạn có ý định mở dữ liệu về con người, hãy cân nhắc tới những lợi ích của xã hội và rủi ro gây hại cho những con người đó. Quan trọng hơn, để dữ liệu có nguồn gốc từ dữ liệu cá nhân trở thành dữ liệu mở, kỹ thuật ẩn danh thường được sử dụng.
Ẩn danh là gì?
Ẩn danh là một quy trình gồm nhiều hành động. Ẩn danh không chỉ là về kỹ thuật, không chỉ là công cụ, và không chỉ là tập hợp các phương trình toán học. Ẩn danh liên quan tới nghiên cứu, các cân nhắc về pháp lý và đạo đức, phân tích và kiểm thử rủi ro. Để ẩn danh hiệu quả, quy trình đó nên bao gồm suy nghĩ nghiêm túc về điều gì xảy ra với dữ liệu sau khi ẩn danh; dữ liệu sẽ được chia sẻ với ai; liệu có những sai lầm nào có thể diễn ra và liệu có biện pháp giảm nhẹ nào có thể tránh được điều đó không.
Nhiều người hiểu một cách quá đơn giản là ẩn danh chỉ là loại bỏ các mã nhận dạng cá nhân (phần lớn là tên người) khỏi các tập hợp dữ liệu. Kỹ thuật ‘bỏ nhận dạng’ (de-identification) này có thể thích hợp trong một vài nhưng không phải tất cả các trường hợp. Trong an toàn dữ liệu, kĩ thuật này thậm chí được coi là rất hạn chế, nếu chỉ bỏ mỗi mã nhận dạng như tên hay số căn cước công dân chẳng hạn, thì các thông tin còn lại trong tập hợp dữ liệu đó vẫn có thể giúp người khác tái nhận diện cá nhân đó.
Ẩn danh đã trở thành một lĩnh vực lớn với đa dạng các kĩ thuật được phát triển liên tục trong hàng thập kỉ qua. Các kĩ thuật ẩn danh có thể tạm thời chia thành ba loại:
Ngăn chặn (Suppression): loại bỏ các mã nhận dạng hoặc các mẩu thông tin có thể dẫn đến việc tái nhận dạng.
Thường hóa (Generalisation): tổng hợp các điểm dữ liệu sao cho mức độ chi tiết thô hơn hoặc loại bỏ các chi tiết để che khuất đi dữ liệu về con người trên cơ sở từng cá nhân.
Gián đoạn (Disruption): thêm nhiễu và thay đổi các giá trị đến mức ngày càng khó để biết bằng cách nào hoặc liệu có thể khôi phục hoặc suy luận ra thông tin về các cá nhân cụ thể hay không.
Để hiểu hơn về kĩ thuật ẩn danh, chúng ta có thể đến với ví dụ thống kê số buổi làm việc trên trực tuyến trong tuần sau đây:
Trong ví dụ này, giả thiết một tổ chức tiến hành khảo sát tất cả các nhân viên của mình để thu thập dữ liệu về số buổi làm việc trên trực tuyến theo tuần nhằm tối ưu hóa chi phí văn phòng. Bây giờ, họ đang xem xét liệu có thể phát hành một phiên bản ẩn danh kết quả khảo sát để có thể chia sẻ lợi ích cho các công ty khác hay không.
Dữ liệu thô có thể thấy giống như thế này:
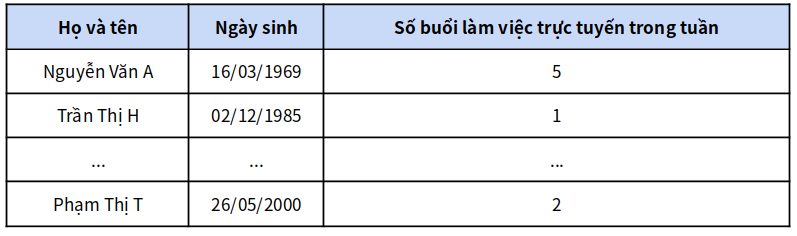
Người quản trị dữ liệu (người thu thập, duy trì và chia sẻ dữ liệu) với trách nhiệm phát hành phiên bản ẩn danh dữ liệu này, có thể quyết định bước kỹ thuật đầu tiên là loại bỏ tất cả các tên (ngăn chặn), thay thế chúng bằng các mã nhận dạng giả (giả danh hóa – pseudonymisation - một dạng của ngăn chặn):

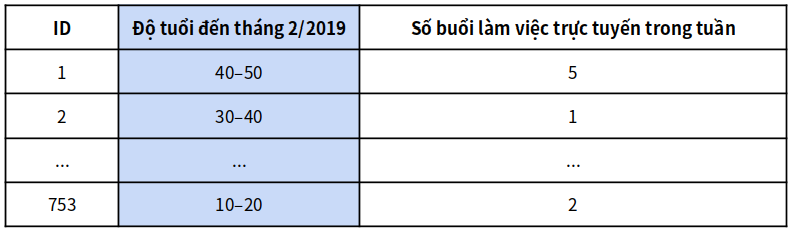
Tuy nhiên, loại bỏ tên vẫn có thể chưa đủ. Nếu bạn biết ngày sinh của đồng nghiệp mình, bạn có thể dễ dàng nhận dạng ra họ trong dữ liệu đó, và suy luận ra thói quen làm việc trực tuyến của họ như thế nào. Người quản lý dữ liệu vì thế có thể quyết định cũng thay thế các ngày sinh rất chính xác đó bằng độ tuổi (generalization - thường hóa):
Giả thiết thông tin về số buổi làm việc trực tuyến trong tuần là rất nhạy cảm, nên họ cũng có thể muốn thêm “nhiễu” vào dữ liệu đó, ví dụ bằng việc hoán đổi các giá trị với một tỷ lệ nhất định (sự gián đoạn):

Mỗi lần lặp lại đó sẽ dẫn đến một dạng "dữ liệu được ẩn danh" - cũng như sự kết hợp vô hạn của các kỹ thuật ẩn danh.
Với từng bước như vậy, người quản lý dữ liệu đã loại bỏ được lượng nhất định các chi tiết, mức độ chi tiết và độ chính xác từ dữ liệu đó. Điều này ngụ ý dữ liệu đó là ít đặc thù hơn và ít chính xác hơn. Ẩn danh làm giảm ‘tiện ích’/tính hữu dụng của dữ liệu đó.
Tiện ích (Utility) là khái niệm tương đối: sau 2 bước ẩn danh đầu tiên ở trên, tập hợp dữ liệu đó sẽ là ít hữu dụng hơn cho ai đó cần trả lời cho câu hỏi: “Ông A có bao nhiêu buổi làm việc trên trực tuyến trong tuần?”, nhưng tiện ích có thể vẫn là cao cho ai đó cố trả lời câu hỏi về việc liệu, trong tập hợp dữ liệu này, những người ở độ tuổi 20 làm việc trên trực tuyến nhiều hơn hay ít hơn so với những người ở độ tuổi 50.
Dĩ nhiên dữ liệu thô đầy đủ, không được ẩn danh có thể là dữ liệu có giá trị lớn nhất vì nó cho phép đa dạng mục đích và khả năng sử dụng lớn nhất có thể. Và ở một cực khác, tiện ích có thể không còn lại gì mấy nếu ẩn danh nặng tới mức nó trả về dữ liệu vô dụng, như trong ví dụ (cực đoan) này:

Từ ví dụ này cho thấy, kỹ thuật ẩn danh đối với một tập hợp dữ liệu thô có thể là vô tận. Càng nhiều kỹ thuật ẩn danh được áp dụng, tính hữu dụng của dữ liệu sẽ càng ít đi. Vì thế, có thể nói rằng: “Dữ liệu có thể hoặc hữu dụng hoặc được ẩn danh tuyệt vời, nhưng không bao giờ có cả hai”.
Dữ liệu mở và rủi ro tái nhận dạng
Ẩn danh dữ liệu ở mức nào là sự cân nhắc vừa đánh đổi giữa rủi ro và tiện ích nhưng cũng vẫn đảm bảo sự tuân thủ với các luật và quy định bảo vệ dữ liệu. Quyết định này không chỉ dựa vào đánh giá bản thân nội dung dữ liệu mà còn bao gồm các nguy cơ trong ngữ cảnh mà dữ liệu đó được sử dụng, như dữ liệu sẽ được chia sẻ với ai, khi nào và như thế nào. Tiện ích càng nhiều thì rủi ro càng lớn, và ngược lại. Khi ẩn danh đạt tới mức độ không còn rủi ro, thì cũng là lúc dữ liệu được ẩn danh trở thành vô dụng!
Một trong những quan điểm ẩn danh dữ liệu là coi phổ dữ liệu (Hình 2) cũng chính là phổ mức độ quản trị dữ liệu và mức độ chắc chắn về những rủi ro mà dữ liệu cá nhân có thể bị xâm phạm. Theo đó:
Cực đóng của phổ dữ liệu có sự chắc chắn nhất về ai có thể truy cập và sử dụng dữ liệu đó, và sự điều hành khắt khe nhất về truy cập, các quyền, .v.v.
Khi dữ liệu ở dạng chia sẻ, dù đã quy định ai có thể truy cập và sử dụng dữ liệu đó và khi nào, nhưng vẫn tiềm tàng sự không chắc chắn ở mức độ nhất định, và vì thế vẫn phải giảm nhẹ rủi ro qua vài bước ẩn danh.
Cực mở của phổ dữ liệu tạo ra tiềm năng lớn nhất cho truy cập, sử dụng và xử lý, nhưng quản trị càng dễ dàng thì mức độ không chắc chắn về rủi ro dữ liệu cá nhân bị xâm phạm càng cao.
Có thể nói rằng, luôn luôn tồn tại khả năng dù lớn hay nhỏ, có một kẻ tấn công có động lực lớn, kĩ năng cao, nhiều nguồn lực để tái nhận diện những dữ liệu ẩn danh. Bởi vậy, phần lớn các dữ liệu ẩn danh đều được quản trị và kiểm soát hết sức nghiêm ngặt. Tuy nhiên, vẫn có một số ví dụ về dữ liệu ẩn danh vừa mở nhưng vừa duy trì được tính tiện ích đáng kể. Một trong số đó là dữ liệu thống kê.
Khi các cơ quan thống kê phát hành dữ liệu định kì, các dữ liệu này có rủi ro thấp tới mức không ai dám “cãi” điều này sẽ xâm phạm đến quyền riêng tư. Theo các nhân viên thống kê của chính phủ Anh, điều này có thể được lí giải như sau:
Trước hết, những người chuyên nghiệp về số liệu thống kê có hiểu biết sâu sắc về kiểm soát công bố số liệu thống kê, trong đó bao gồm các phương pháp nhằm đảm bảo tổng hợp số liệu thống kê không vô tình tiết lộ thông tin về các cá nhân.
Thứ hai, các cơ quan thống kê hiểu biết sâu sắc về sự cân bằng giữa quyền riêng tư và các quyền cũng như các kết quả đầu ra khác.
Cuối cùng, dù các dữ liệu đã trải qua quy trình xử lý khiến các tiện ích đã sụt giảm đáng kể nhưng vì quy mô dữ liệu cực lớn nên nó vẫn vô cũng giá trị với cộng đồng.
Nên hiểu rằng những lí do này không chỉ phù hợp với các cơ quan thống kê của nhà nước mà cũng đúng với cả khối tư nhân. Các công ty hoàn toàn có thể chia sẻ dữ liệu mở[7] liên quan đến hoạt động của họ vì mục đích minh bạch, nhưng các dữ liệu này hoàn toàn có thể được thu thập và xử lý ở mức gần như loại bỏ hoàn toàn các thông tin nhạy cảm.
----
Ẩn danh là quy trình loại bỏ thông tin cá nhân có thể nhận dạng được khỏi dữ liệu. Vì thế, dữ liệu đó không còn được tham chiếu tới như là “dữ liệu cá nhân” và không còn phải tuân thủ với GDPR. Bằng việc đảm bảo rằng dữ liệu cá nhân được xử lý minh bạch, nghiêm ngặt tuân theo GDPR, nó có thể làm giảm rào cản xuất bản và sử dụng lại dữ liệu nói chung, Dữ liệu Mở nói riêng. Vì thế, GDPR có thể tạo thuận lợi cho nền kinh tế do dữ liệu dẫn dắt, sinh ra các sản phẩm và dịch vụ mới để tạo ra giá trị cho xã hội, trong khi vẫn tôn trọng các quyền của công dân[8].
Các chú giải
[1] Open Data Institute: What makes data open?: https://theodi.org/article/what-makes-data-open/
[2] European Union (2016): Regulation (EU) 2016/679 (General Data Protection Regulation) Art 4. Definitions: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679
[3] Ngân hàng Nhà nước Việt Nam: Thông tư 31/2015/TT-NHNN Quy định về đảm bảo an toàn, bảo mật hệ thống công nghệ thông tin trong hoạt động ngân hàng do Thống đốc Ngân hàng Nhà nước ban hành. Xem Điều 2, khoản 8: https://thukyluat.vn/vb/thong-tu-31-2015-tt-nhnn-dam-bao-an-toan-bao-mat-he-thong-cntt-trong-ngan-hang-49223.html#dieu_2-8
[4] Office for National Statistics (2009): National Statistician’s Guidance on Confidentiality of Official Statistics: https://gss.civilservice.gov.uk/wp-content/uploads/2012/12/Confidentiality-of-Official-Statistics-National-Statisticians-Guidance.pdf
[5] Information Commissioner’s Office (2018), ‘Guide to Data Protection’: https://ico.org.uk/for-organisations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/lawful-basis-for-processing/special-category-data/#scd1
[6] Open Data Institute (2016): The Data Spectrum: https://theodi.org/about-the-odi/the-data-spectrum/
[7] Syngenta (2018): ‘Open data agriculture’: https://www.syngenta.com/who-we-are/our-stories/open-data-agriculture
[8] data.europa.eu: Protecting data and opening data: General Data Protection Regulation (GDPR) as a supporter for Open Data: https://data.europa.eu/en/datastories/protecting-data-and-opening-data. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/du-lieu-mo/bao-ve-du-lieu-va-mo-du-lieu-634.html
![]()
Giấy phép nội dung: CC BY 4.0 Quốc tế
Lê Trung Nghĩa
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Trang Web này được thành lập theo Quyết định số 142/QĐ-HH do Chủ tịch Hiệp hội các trường đại học, cao đẳng Việt Nam – AVU&C (Association of Vietnam Universities and Colleges), GS.TS. Trần Hồng Quân ký ngày 16/09/2019, ngay trước thềm của Hội thảo ‘Xây dựng và khai thác tài nguyên giáo dục mở’ do 5...
 Tài nguyên bổ sung. Nghiên cứu Mở (P2PU)
Tài nguyên bổ sung. Bộ công cụ Học tập Trực tuyến
Tài nguyên bổ sung. Nghiên cứu Mở (P2PU)
Tài nguyên bổ sung. Bộ công cụ Học tập Trực tuyến
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No3/2026 tại Trường Đại học Nguyễn Tất Thành, 10 và 17/06/2026. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No3/2026 tại Trường Đại học Nguyễn Tất Thành, 10 và 17/06/2026. Ngày 1.
 Blog “Phần mềm Tự do Nguồn mở cho Việt Nam” 19 năm tuổi
Blog “Phần mềm Tự do Nguồn mở cho Việt Nam” 19 năm tuổi
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2026 tại Trường Đại học Nguyễn Tất Thành, 09 và 16/06/2026. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2026 tại Trường Đại học Nguyễn Tất Thành, 09 và 16/06/2026. Ngày 1.
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No1/2026 tại Trường Đại học Nguyễn Tất Thành, 08 và 15/06/2026. Ngày 1.
Tài nguyên bổ sung. Độc giả của Giáo dục mở
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No1/2026 tại Trường Đại học Nguyễn Tất Thành, 08 và 15/06/2026. Ngày 1.
Tài nguyên bổ sung. Độc giả của Giáo dục mở
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc; Tín hiệu CC
 Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
Bộ các tài liệu hướng dẫn của UNESCO cho các chính phủ và cơ sở để triển khai Khuyến nghị Tài nguyên Giáo dục Mở
 Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
Hướng dẫn thực hành về Giáo dục Mở cho các học giả: Hiện đại hóa giáo dục đại học thông qua các thực hành Giáo dục Mở (dựa trên Khung OpenEdu)
 Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
Các mô hình bền vững Tài nguyên Giáo dục Mở (TNGDM) - Tổng hợp
 ORCID - Quy trình làm việc
ORCID - Quy trình làm việc
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
Europeana - mô hình mẫu về hệ thống liên thông, Dữ liệu Mở (Liên kết) và dữ liệu FAIR của OpenGLAM/Văn hóa Mở
 Loạt bài về Khoa học Mở (KHM): Định nghĩa các khái niệm của KHM; Bộ công cụ KHM của UNESCO bản tiếng Việt; Năm KHM và chuyển đổi sang KHM;
Loạt bài về Khoa học Mở (KHM): Định nghĩa các khái niệm của KHM; Bộ công cụ KHM của UNESCO bản tiếng Việt; Năm KHM và chuyển đổi sang KHM;
 ‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
‘ĐÁNH DẤU KHÓA HỌC MỞ VÀ KHAM ĐƯỢC: CÁC THỰC HÀNH TỐT NHẤT VÀ CÁC TRƯỜNG HỢP ĐIỂN HÌNH’ - VÀI THÔNG TIN HỮU ÍCH
 Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
Khóa học cơ bản về Dữ liệu Mở trong chương trình học tập điện tử trên Cổng Dữ liệu châu Âu
 Các thành phần cơ bản trong kế hoạch tổng thể xây dựng chính sách tài nguyên giáo dục mở – OER (Open Educational Resources) - bản toàn văn
Các thành phần cơ bản trong kế hoạch tổng thể xây dựng chính sách tài nguyên giáo dục mở – OER (Open Educational Resources) - bản toàn văn